

Intro
On November 28, 2022, OpenAI released their newest GPT-3 model, davinci-003, which is being referred to as “GPT-3.5”. In their newsletter, they described it as follows:
We’re excited to announce the release of the newest addition to the GPT-3 model family: `text-davinci-003`. This model builds on top of our previous InstructGPT models, and improves on a number of behaviors that we’ve heard are important to you as developers.
`text-davinci-003` includes the following improvements:
It produces higher quality writing. This will help your applications deliver clearer, more engaging, and more compelling content.
It can handle more complex instructions, meaning you can get even more creative with how you make use of its capabilities now.
It’s better at longer form content generation, allowing you to take on tasks that would have previously been too difficult to achieve.
We at Intento tried the new model right away, got excited, and found it helpful for various Source Quality Improvement and Automatic Post-Editing tasks in our workflows.
A few questions still remain:
- Can GPT-3 be used as a Machine Translation model?
- How does GPT-3’s translation performance compare to more narrow MT models, such as Google and DeepL?
- What is the translation quality like for specialized content domains, such as Healthcare or Legal?
- What would be the cost per million characters for GPT-3 translation?
Once the end-of-year MT deployment projects were finished, our AI Curation team had the opportunity to experiment with GPT-3 and assess its performance on our State of the Machine Translation 2022 benchmark dataset for a few languages. Keep reading!
General domain translation
Experimental setting
For the general domain translation, we chose the English-to-Spanish and English-to-German directions. We took 500-segment samples with reference translations from our State of the Machine Translation 2022 benchmark for each direction. We utilized GPT-3 hosted by OpenAI, model davinci-003, with a temperature set to 0 for reproducible results.
We decided to evaluate different prompts to make GPT-3 produce translations.
PROMPT 1: Translate this from English to {TARGET_LANGUAGE}:\n"""{SEGMENT}""" PROMPT 2: The following is the text """{SEGMENT}""" translated from English to {TARGET LANGUAGE}: """ PROMPT 3: English text: """{SEGMENT}"""\nTranslation into {TARGET_LANGUAGE}: """ PROMPT 4: English: """{SEGMENT}"""\n{TARGET_LANGUAGE}: """ PROMPT 5: TARGET_LANGUAGE_LOCAL = "Español" English: """{SEGMENT}"""\n{TARGET_LANGUAGE_LOCAL}: """
For each prompt, we conducted three translations to assess output variability.
We compared GPT-3 translations to translations done by well-known stock MT engines, such as Amazon, Apptek, Baidu, DeepL, Google, IBM, Microsoft, ModernMT, Niutrans, Systran, and Ubiqus.
To evaluate MT quality, we utilized the same version of the reference-based COMET score as we used in our September report. There’s a more recent version of COMET published in December 2022, but we do not expect results to be vastly different.
Translation variability
With the temperature set to 0, we found no translation variability for the same prompt. We also ran a wider study for the variability and found only one case in the financial domain where GPT-3 produced at random either “16 millones de euros y 139 millones de euros” or “€16m y €139m”.
Between different prompts, 35-45% of translations are different. Overall, the differences are in capitalization, word order, DNT terminology, mostly unwarranted, and punctuation. In most cases, except DNT terms, there is no large impact on the overall translation quality. For German, the biggest issues are grammatical errors for some attempts in some prompts and questionable choices of verbs, i.e. some lexical mistakes. However, overall, the quality is quite solid, and we could detect no critical issues.
Translation performance and reliability
Translation of a 500-segment dataset typically took about 30 minutes, or 3–4 seconds per segment, which is about 10 times slower than most of the stock Machine Translation models. During translations, we have registered many API errors, requiring multiple retries. We’re planning to check if GPT-3 deployed at Azure produces fewer errors.
Translation quality
Based on the COMET scoring, there’s no significant difference between the above prompts.
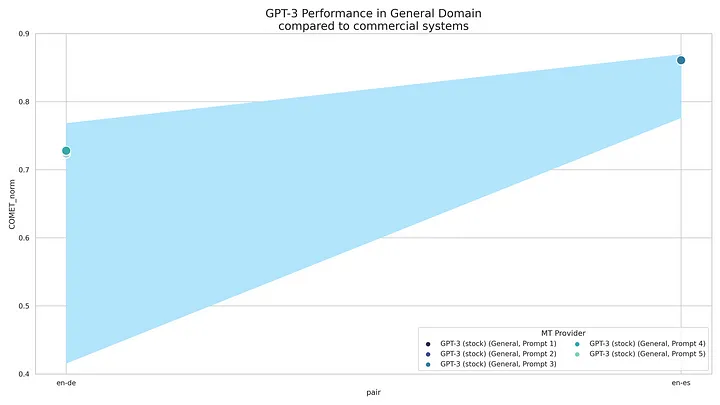
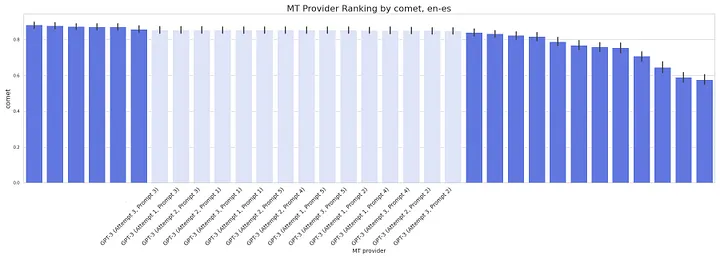
For English => Spanish, GPT-3 performed close to the top-runners (Google, Amazon, DeepL, Microsoft, and ModernMT). However, its average score value was on the lower side.
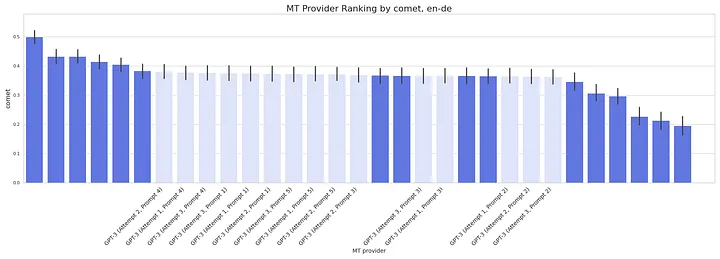
For English => German, GPT-3 is in the second tier, with scores significantly lower than the top-runners (DeepL, Google, Amazon, and Microsoft).
Specific GPT-3 translation mistakes in Spanish
Human LQA of the Spanish translation by GPT-3 identified a few issues: mostly some omissions, false DNTs, some terminology mistakes, and some questionable grammar. Prompt 2 produced significantly fewer critical issues.
Sample GPT-3 mistranslation for English => Spanish
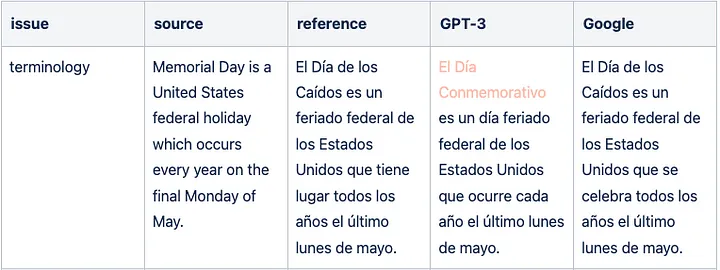
Sample GPT-3 translation false DNT issue for English => Spanish
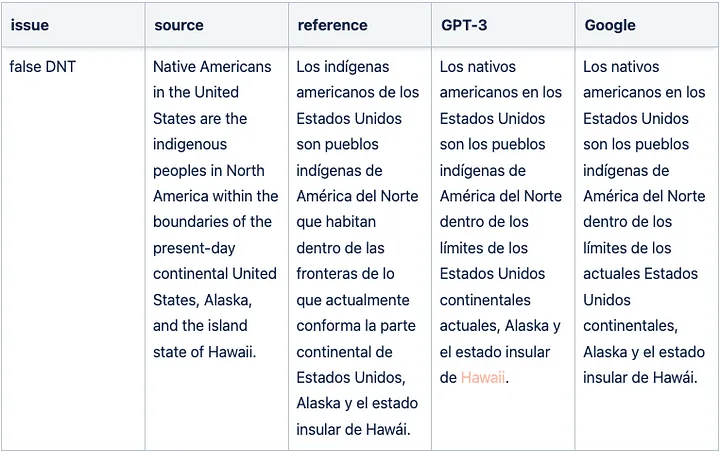
Sample GPT-3 translation grammar issue for English => Spanish
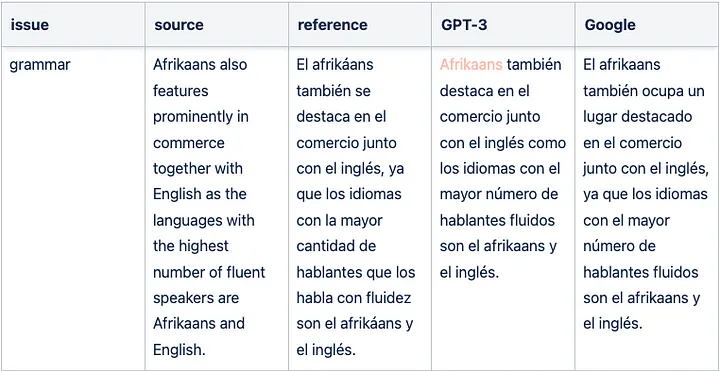
Sample literal GPT-3 translation issue for English => Spanish
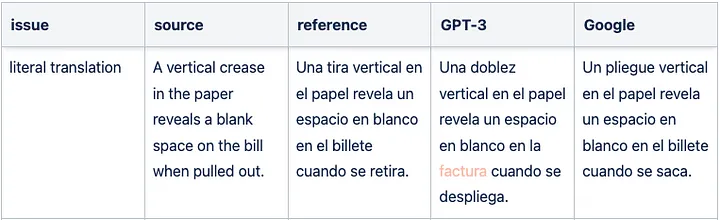
Sample GPT-3 translation omission for English => Spanish
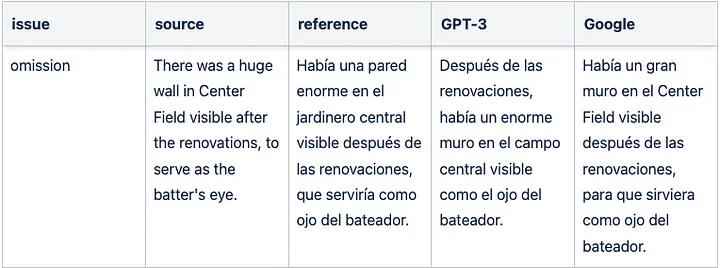
Specific GPT-3 translation mistakes in German
GPT-3 translation from English to German has a large number of literal translations, some mistranslations, DNT, and terminology issues.
Sample GPT-3 mistranslation for English => German

Sample GPT-3 translation False DNT issue for English => German
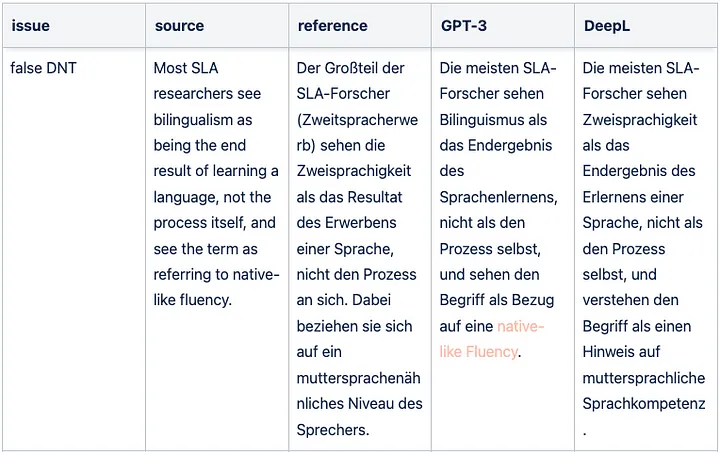
Sample GPT-3 translation grammar issue for English => German
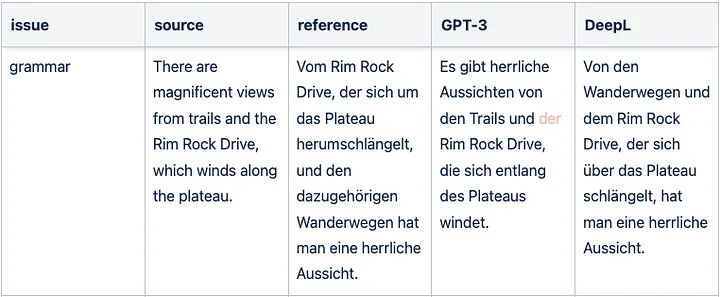
Sample GPT-3 translation terminology issue for English => German
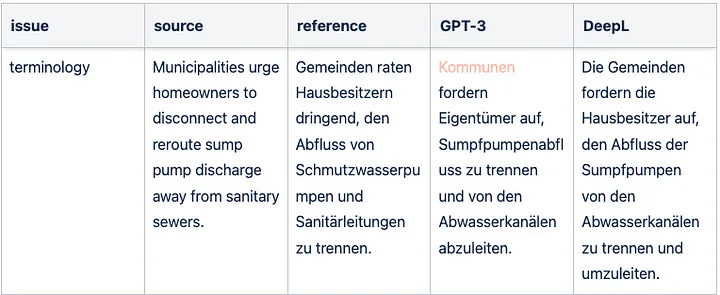
Sample GPT-3 translation omission issue for English => German
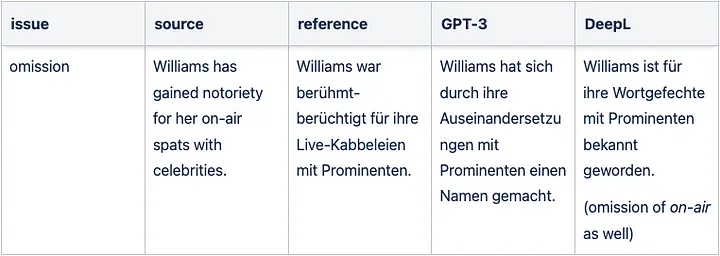
In-domain translation
Here we picked German (as a language where we see more challenge) and translated Legal and Healthcare domains (500 segments each) with the shortest general-domain prompt below (as they performed about the same) and a few variations of domain-specific prompts.
Prompts for domain-specific translation
PROMPT 1: (non-domain-specifc prompt) English: """{SEGMENT}"""\n{TARGET_LANGUAGE}: """ PROMPT 2: Translate this from English to {TARGET_LANGUAGE}, topic - {DOMAIN}:\n"""{SEGMENT}""" PROMPT 3: English {DOMAIN} text: """{SEGMENT}"""\nTranslation into {TARGET_LANGUAGE}: """ PROMPT 4: English text: """{SEGMENT}"""\nTranslation into {TARGET_LANGUAGE} using {DOMAIN} terminology: """ PROMPT 5: English text with {DOMAIN} terminology: """{SEGMENT}"""\nTranslation into {TARGET_LANGUAGE}: """ PROMPT 6: English ({DOMAIN}): """{SEGMENT}"""\n{TARGET_LANGUAGE} ({DOMAIN}): """
GPT-3 translation variability
In terms of prompt variability, prompt 2 has 0 correlation with the rest because it adds unnecessary \n\n. The rest of the prompts somewhat correlate, with 30–40% of translations being the same.
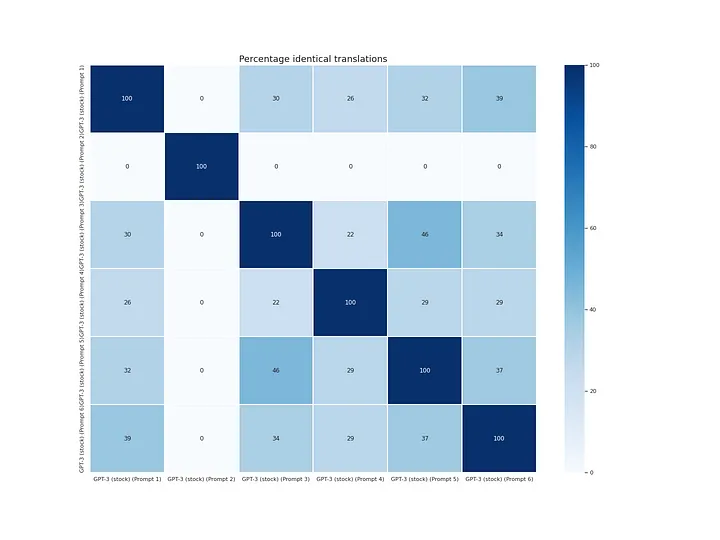
GPT-3 output variability for Healthcare texts
GPR-3 translation quality for domain-specific texts
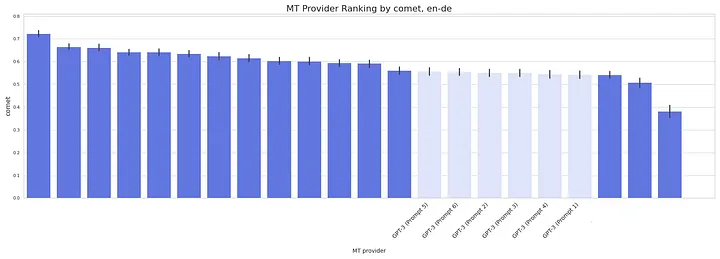
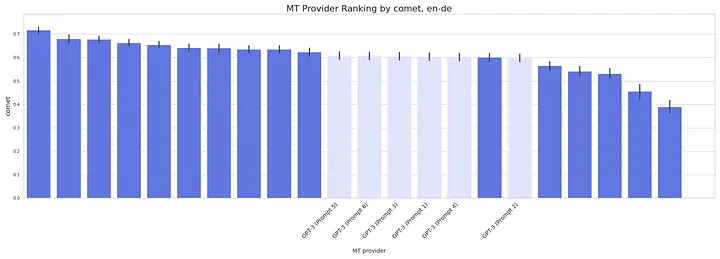
GPT-3 scored quite low for all prompts we tried compared to general-purpose stock MT engines. The domain-less prompt 1 is last among all prompts or in the bottom half. Prompt 5 produces the highest-ranking translations.
Performance chart for Legal content:
Performance chart for Healthcare content:
GPT-3 translation errors for domain-specific texts
In the Legal domain, there is one sentence where the first half does not make sense, and several mistranslations, literal translations, omissions, grammatical issues, and repetitions.
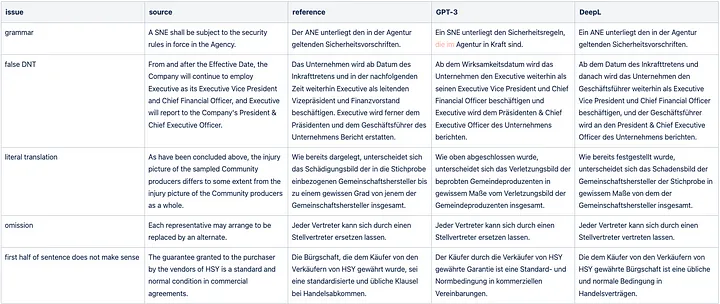
Sample GPT-3 translation issues for Legal domain.
In Healthcare, the situation is slightly better, with fewer moderate issues. There are still literal translations, mistranslations, some terminology issues, and some grammatical issues. Overall, we can conclude that there are issues, but they do not severely hinder the meaning of the segments.
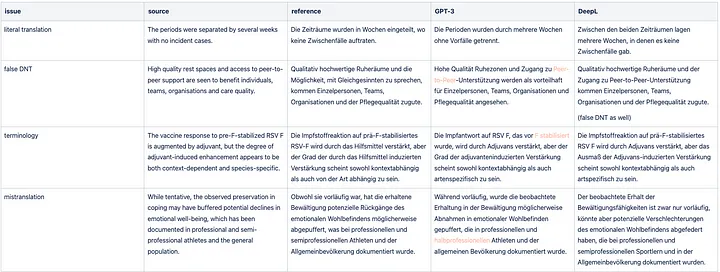
Sample GPT-3 translation issues for the Healthcare domain.
GPT-3 Translation Costs
We have divided total costs as presented in the OpenAI console by the amount of content we translated via GPT-3 davinci model for this experiment (without prompt templates) and estimated the average translation cost to be $12 per 1M characters.
Conclusions
GPT-3 offers a way to translate text between languages using an API. There are a few different prompts available, but the translation results between them are usually quite similar.
We found that GPT-3 translations are among the best commercial MT engines for English to Spanish, but they fall into the second tier for English to German.
When it comes to domain-specific texts such as Legal and Healthcare, GPT-3 translations are not up to par, even when using domain-specific prompts. In these cases, stock, general-purpose MT engines perform much better. Check out our yearly State of the MT report to figure out which engines to utilize for your language pairs and domains.
As of today, GPT-3 deployed at OpenAI for translation works significantly slower than commercial MT engines, resulting in a considerable number of API errors.
At the same time, in our other experiments, we found GPT-3’s performance on same-language text rewriting and stylization quite remarkable. Additionally, multilingual content generation yielded generally good results. The translation task likely presents a unique challenge, requiring both creativity and stringent requirements for the output, making it more difficult for GPT-3 than other tasks.
We’re planning to keep running experiments with the refined versions of GPT-3, as well as the upcoming GPT-4. Keep an eye out!


