

In 2023, as new Generative AI models emerged, we rigorously tested their translation capabilities and shared our findings in three blog posts (gpt-3, gpt-3.5, gpt-4) and our annual State of the Machine Translation report.
As the year drew to a close, the GenAI field saw a flurry of exciting updates, including new models from Anthropic, Google, and OpenAI. Rather than waiting for our next annual report, we conducted a dedicated study immediately. Here are the results!
Experimental setting
GenAI models
We’ve chosen 9 out of all the available large language models (LLMs) for this study:
- claude-2.1 (Anthropic)
- gpt-4–1106-preview (OpenAI)
- gpt-4 (upd June 2023) (OpenAI)
- gpt-3.5-turbo (updated June 2023) (OpenAI)
- llama-2–70b-chat-hf (Meta AI)
- text-bison@002 (PaLM 2 — Google)
- chat-bison@002 (PaLM 2 — Google)
- text-unicorn@001 (PaLM 2 — Google)
- gemini-pro (Google)
We have also added eight specialized Machine Translation models for comparison:
- Alibaba Cloud E-Commerce Edition
- Amazon Translate
- Baidu Translate API
- DeepL API
- Google Cloud Advanced Translation API
- Microsoft Translator API v3.0
- ModernMT Enterprise Edition
- SYSTRAN PNMT API
As you may see, out of the whole zoo of open-source LLMs we chose just one for this experiment (LLaMA 2). It outperforms all other open-source models in multilingual capabilities based on multiple internal evaluations. However, it still falls short compared to commercial models in this aspect.
Datasets
Just like our past research, we utilized a portion of our Machine Translation dataset, developed in collaboration with e2f. We focused on English-to-Spanish and English-to-German translations, conducting two sub-studies: General domain translation (both EN>ES and EN>DE), and Domain-specific translation (Legal and Healthcare for the EN>DE pair).
Prompts
When engineering prompts, we adhered to the top guidelines for using LLMs as MT. We also leaned on our past research experience with GPT models.
Since LLMs are mainly built for conversation, they add extra explanations to translations. We had to tackle this in the prompts.
For the general domain, here’s our system message:
You are a professional translator. Translate the text provided by the user from {source_lang} to {target_lang}. The output should only contain the translated text.
For specific domains (Legal and Healthcare):
You are a professional medical translator. Translate the text provided by the user from {source_lang} to {target_lang}. The output should only contain the translated text.
You are a professional legal translator. Translate the text provided by the user from {source_lang} to {target_lang}. The output should only contain the translated text.
It worked well for OpenAI models, but others required additional prompt and software engineering. For example, LLaMA-2 added the following (\n\n(Note:):
Las vistas magníficas se pueden disfrutar desde los senderos y el Rim Rock Drive, que se wind along the plateau. (Note: “”se wind”” is the correct translation of “”winds”” in this context, as it refers to the drive winding along the plateau, rather than the wind blowing.)
Still, the models provided a significant amount of explanations:
- General domain: EN>DE — 70 out of total 473 segments; EN>ES — 70 out of total 471 segments;
- Legal domain EN>DE — 132 out of 484 segments;
- Healthcare domain EN>DE — 112 out of 481 segments.
Since we can configure multi-step translation workflows in Intento Language Hub, we dealt with those additions via post-processing.
In the case of text-bison and text-unicorn, we chose the following prompt as it showed the least issues in translation:
You are a professional translator. Translate the following from {source_lang} to {target_lang}.\\n{source_lang}: {source_segment}\\n{target_lang}:
For chat-bison and gemini-pro we chose the following context:
You are a professional translator. Translate the following from {source_lang} to {target_lang}. Return nothing but the {target_lang} translation.
Evaluation results
We conducted all translations from December 1st to 21st, 2023. Some systems we tested were in limited availability, which may have impacted their performance and accuracy.
Performance
One of the biggest hurdles in using GenAI for translation is its slow speed, so let’s start there. In the image below, we’re using a logarithmic scale for clarity.
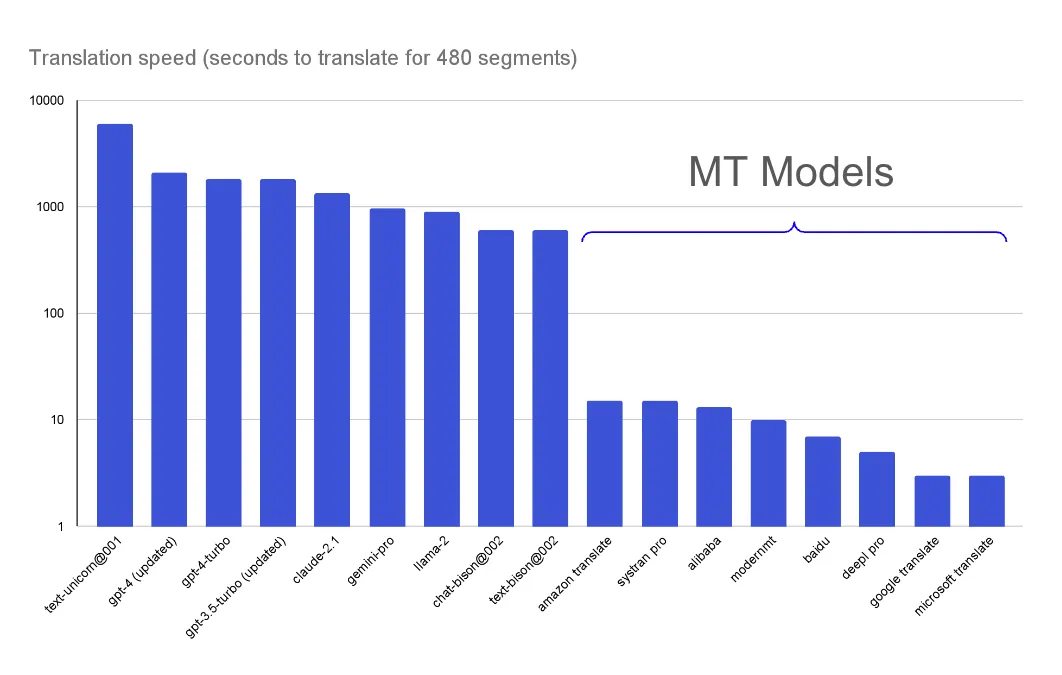
Time to translate 480 segments in seconds.
As we can see, LLMs are significantly slower (100–1000 times) than specialized models.
It’s important to note that the translation speed of gemini-pro and text-unicorn@001 was greatly impacted by limited data processing quotas at the time.
Translation quality — COMET
Just like in our past tests with GPT-3, GPT-3.5, and GPT-4, we’ve used a COMET semantic similarity score to gauge how closely the machine translations match the original human reference.
General Domain translation, English to Spanish
Translating English to Spanish for general content is considered one of the “easiest” tasks due to the wealth of training data available. Many current machine translation models perform so well that their output is virtually indistinguishable by semantic similarity scores. So, it’s interesting to see models that lag significantly behind the cutting edge.
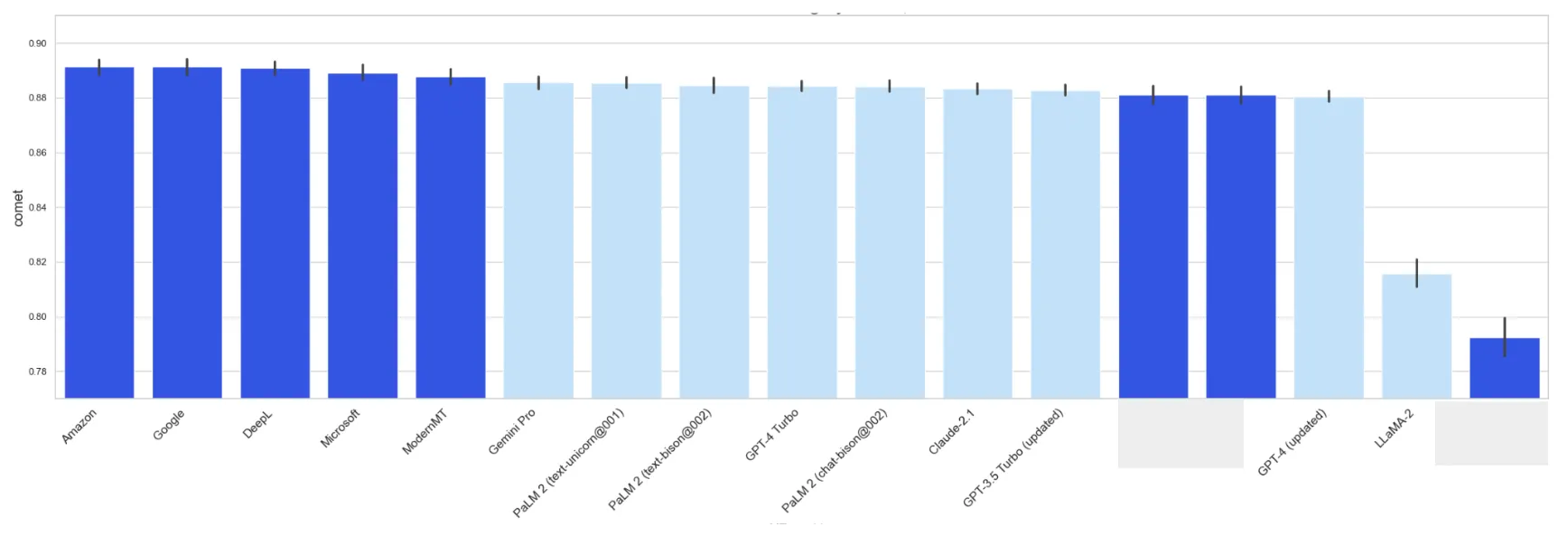
In the image below, the vertical axis shows the average COMET score for a specific model across the test data, with black ticks marking confidence intervals.
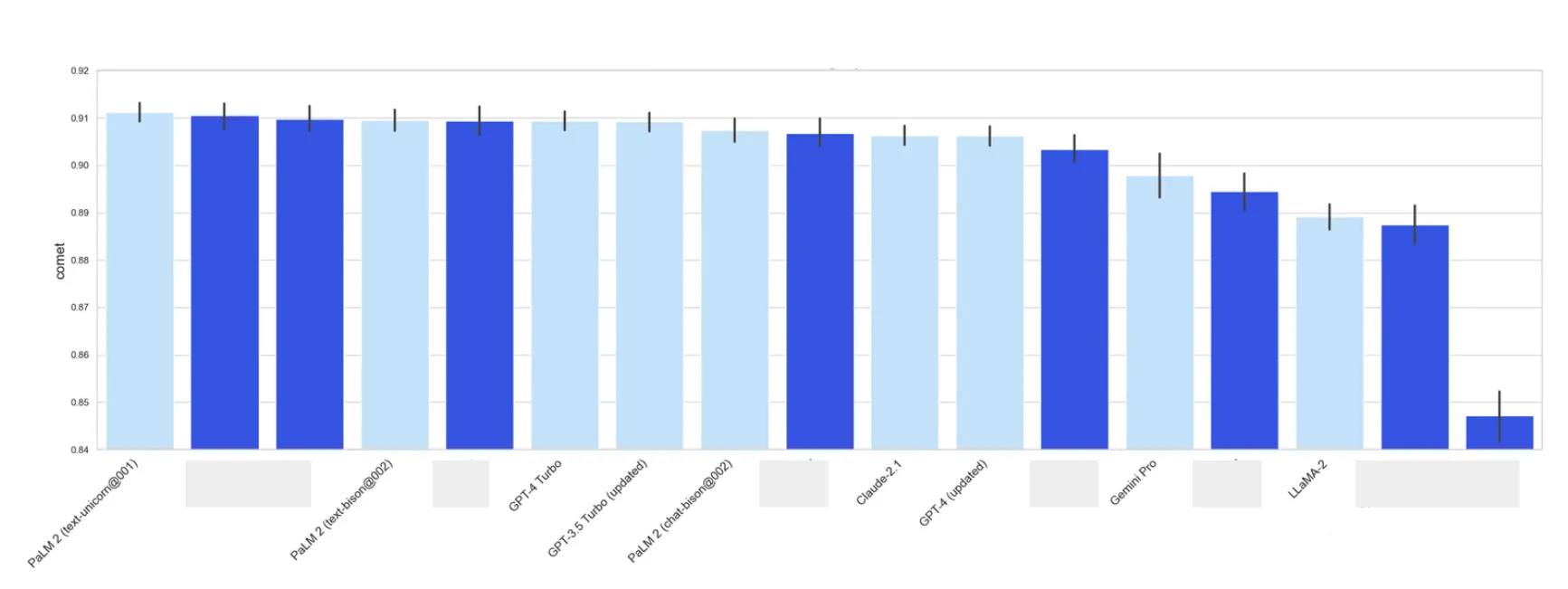
Translation quality for English to Spanish direction, general domain
As you can see, 9 out of the 17 models we tested fall into the same top-tier category. LLaMa2 is the weakest of the LLMs. Both Claude-2.1 and the updated GPT-4 perform notably lower than the best group, but not by a large margin. Interestingly, the updated GPT-4 model underperforms compared to its Turbo version and even GPT-3.5.
You might also notice a broad confidence interval for Gemini Pro. This model often returned empty results for our queries, which likely means safety filters were triggered, even though we set them to their lowest setting, “Block high only”. Aside from this, it’s on par with Claude and the updated GPT-4.
General Domain translation, English to German
Translating English to German is tougher, so it’s useful for pinpointing more sophisticated models.
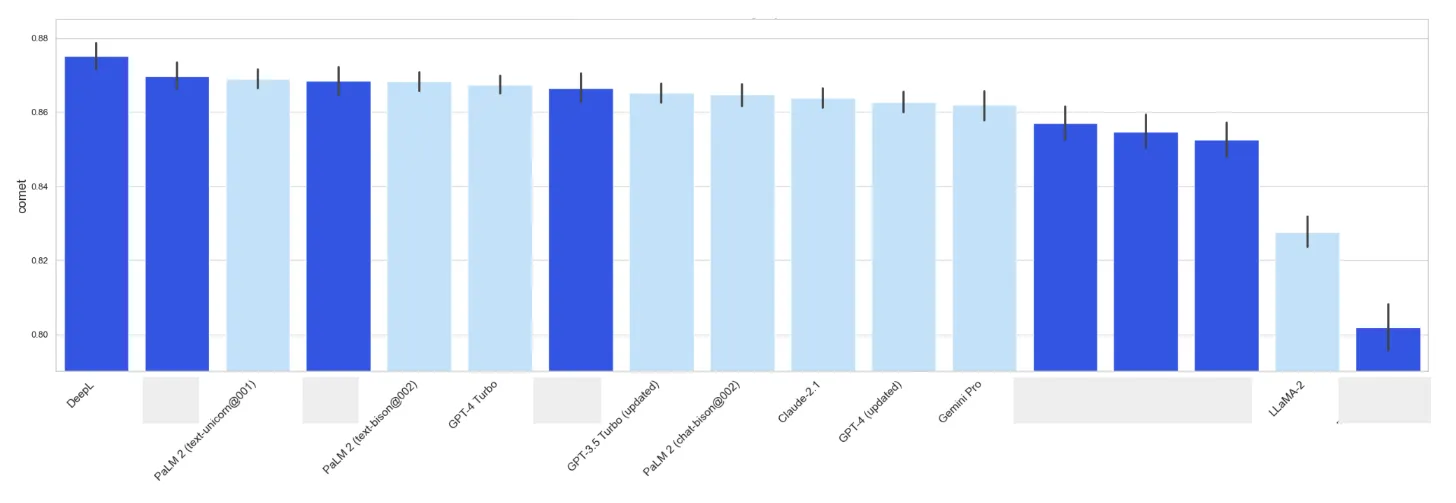
Unsurprisingly, DeepL ranks first, given its German roots and dominance in this language pair.
For the LLMs, the ranking is similar to English to Spanish. One key point for German is that the confidence intervals for the top-performing GenAI are much tighter than for specialized models, showing greater consistency and less variability. This is vital for human post-editing scenarios, where major quality fluctuation increases human review costs.
Healthcare Domain translation, English to German
The way AI vendors gather data for their base models is evident in the translation for specialized fields, particularly when compared to the performance in the same language pairs in a general context. This also indicates whether they’re tracking the model’s performance across different domains or using a single score for all data. However, this can’t be done without extra attention to data labeling.
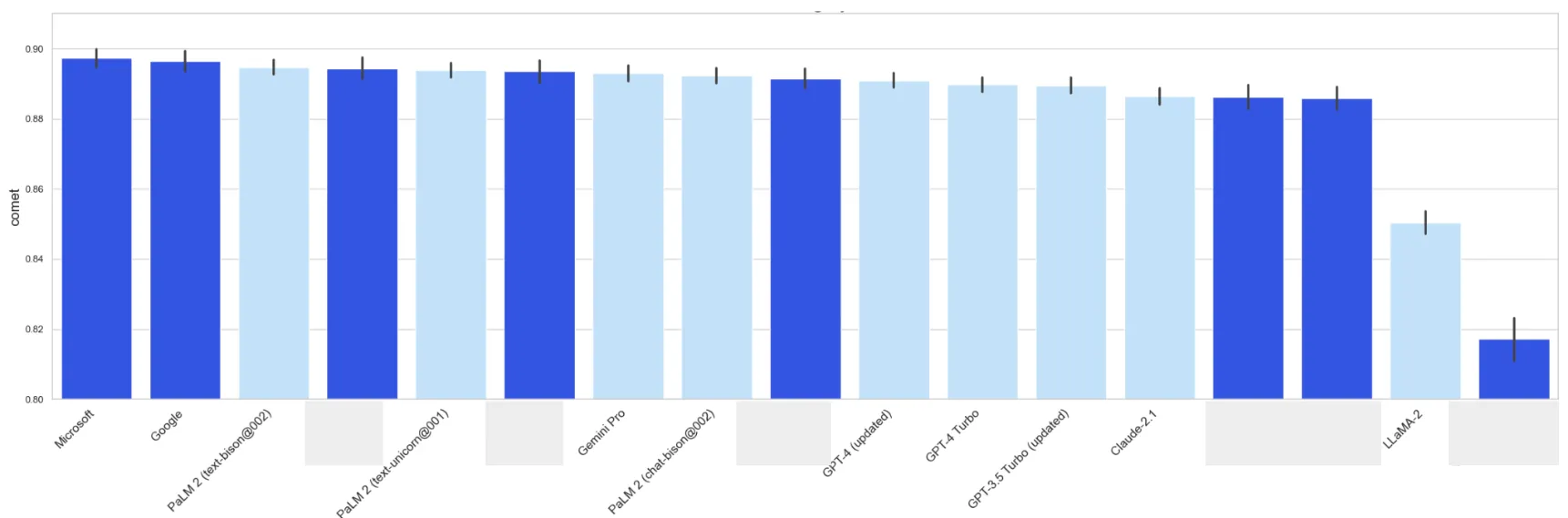
Translation quality for English to German direction, healthcare domain
Translation quality for English to German direction, legal domain
It’s clear that specialized MT models are leading the way, which makes sense. In-domain translation is their main business, particularly in these two areas. For LLMs, translation isn’t the primary function, so targeting specific domains is certainly in the future.
Conclusions based on the semantic similarity scoring
- PaLM 2 models rank highest, leading in EN>ES General domain and closely trailing top performers in General and Healthcare EN>DE translations.
- text-unicorn, the largest PaLM 2 model, scores highest in General domain translations.
- text-bison@002 greatly improves from its first version, ranking first among all LLMs in the EN>DE Healthcare domain.
- chat-bison@002 performs slightly worse but still surpasses most LLMs.
- Despite returning many empty Spanish segments even with “Block high only” safety blocks, Gemini Pro’s quality matches second-tier engines. In the Legal domain for EN>DE, Gemini Pro scores highest among all LLMs studied.
- Claude-2.1 shows similar results and significant improvement from its 2023 run, but still ranks in the second tier.
- LLaMA-2 didn’t achieve top position for any language pairs or domains.
- GPT-4 Turbo scores high and performs best among all GPT models in EN>ES General and EN>DE Legal.
- The updated GPT-4 and GPT-3.5 Turbo show high scores but now rank in the second tier compared to commercial engines.
Weak spot analysis
As shown in the semantic similarity scores, several models reach the top-tier category with no significant statistical differences. Similar to our commercial auto-translation solutions, we also examine the type and extent of translation errors unique to each model.
Translation mistake typology
In this analysis, we identify the following types of translation errors:
- Mistranslation
- Literal translation — a near word-for-word translation that lacks necessary adaptation
- Translated DNT(do-not-translate) — a part of text that should not have been translated (like an acronym or proper noun) was translated
- False DNT —a part of text was mistakenly left untranslated
- Mishandled DNT — DNT was handled inconsistently or incorrectly
- Omission
- Untranslated —the entire text or a significant portion was left in the original language
- Hallucination — a GenAI-specific issue where the output has no relation to the original text
- Punctuation
- Grammar
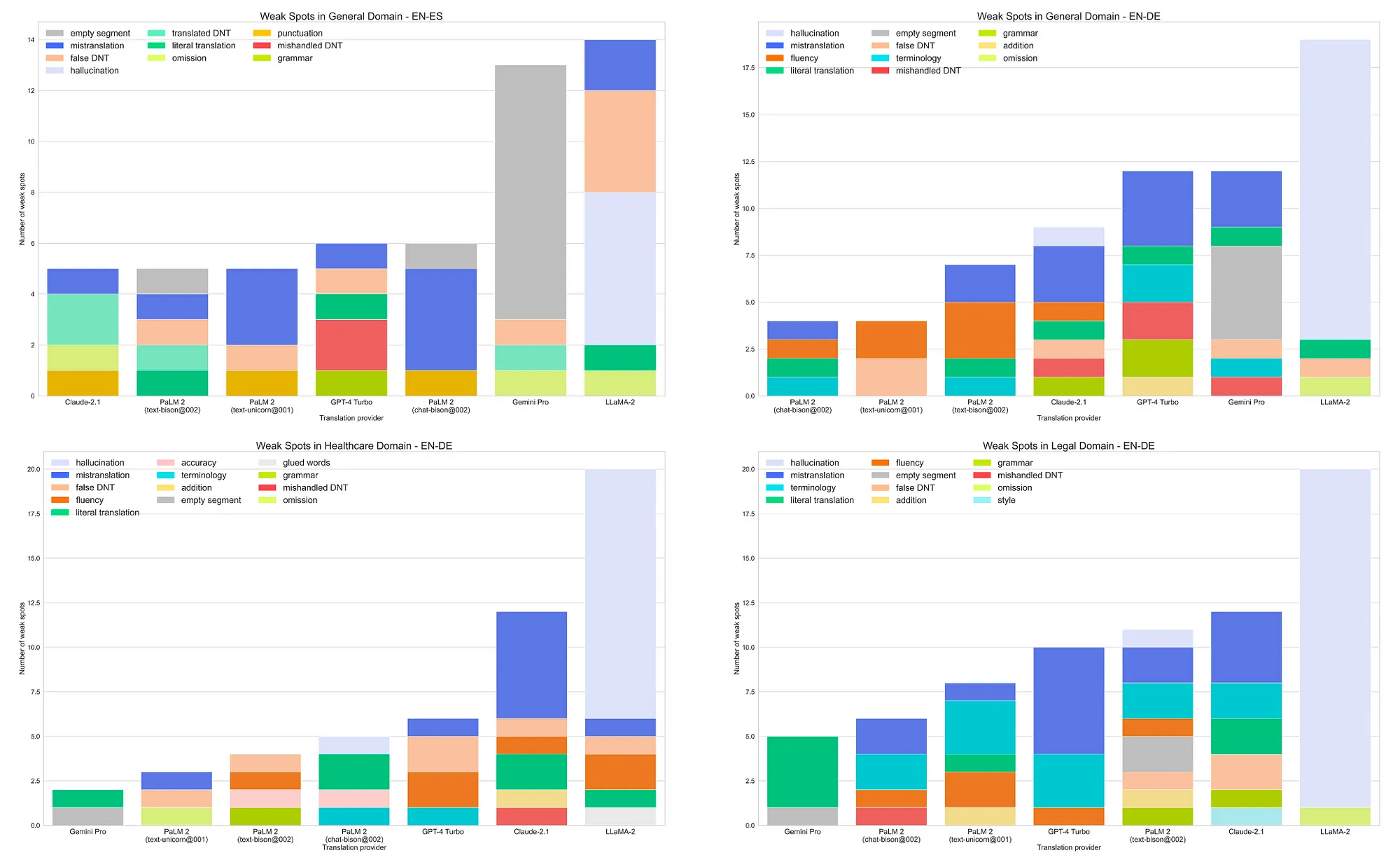
Specific Generative AI translation mistakes for different LLMs
LLaMA-2
In both language pairs, we see a significant number of hallucinations — wrong language for a translation or its part; some translations were a blend of the original text and the translated text; some translations included original segments either preceding or within brackets following the translation. Other problems include fluency issues, omissions, false DNTs, and literal translations.
GPT-4 Turbo
For both language pairs, the model has the following issues: mishandled and false DNTs, terminology issues, mistranslations, and a few literal translations. Some weak spots were paraphrases and issues with the reference/source text.
Claude-2.1
The model has some issues with terminology in Legal and Healthcare domain, mishandled and false DNTs and literal translations causing errors in meaning. Some of the weak spots are paraphrases. When translating Legal and Healthcare content, the model provided full forms of acronyms in translations which seems unnecessary given that acronyms are common in specific domains and usually are not explained.
Overall, the model does not have major issues and hallucinations (there was only a single case of translation that included the source text).
text-bison@002
The model has some terminology problems in the Legal and Healthcare fields, mishandled and false DNTs, and literal translations that lead to errors in meaning. Some of its weak spots are actually paraphrases. In a few instances, the model produced no output. However, it doesn’t have major issues and shows great progress compared to the initial text-bison model.
chat-bison@002
This model’s main shortcomings are primarily literal translations and minor terminology problems. In one instance, it failed to provide a translation. However, the model doesn’t have any significant issues overall.
text-unicorn@001
The model is largely problem-free. However, it does struggle with handling DNTs, has some terminology issues, and occasionally produces literal translations that lack fluency.
Gemini Pro
In most instances of poor scores, there are empty translations due to the malfunctioning safety blockers, even when the “BLOCK_ONLY_HIGH” parameter was set for all possible triggers.
Both language pair models have issues with minor omissions, mistranslations, and occasional literal translations. Some weaknesses were actually paraphrases and problems in the reference/source text.
Gemini Pro showed the fewest translation errors. However, as mentioned earlier, it generates many blank translations due to faulty safety filters. Once these are corrected, we anticipate this model will perform exceptionally well.
Price comparison
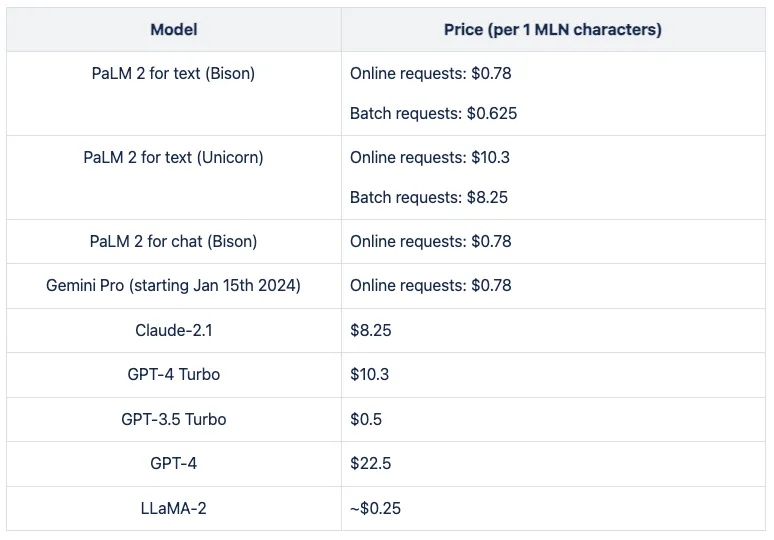
Machine Translation models are priced in USD per 1M of input characters. Generative AI pricing is more intricate, often set per token, with different rates for input and output tokens. Plus, input includes prompts.
To streamline pricing, we convert tokens to words (averaging 4 tokens per word). We also assume the translation length mirrors the source text length. We use the average prompt length in characters (125), figure out the prompt price, and divide that price by 1000, assuming each prompt is used for every 1000 input characters on average. This gives us the formula to calculate the total price:
total_price = input_price + output_price + (125*input_price/1000000*1000)
This results in the following price chart for translating text using generative AI (USD per 1M characters of source text).
Estimated cost of machine translation using LLMs (USD per 1M chars of the source text)
Compared to traditional MT costs, it’s quite appealing. But remember, we must also factor in the speed and quality aspects we discussed earlier:
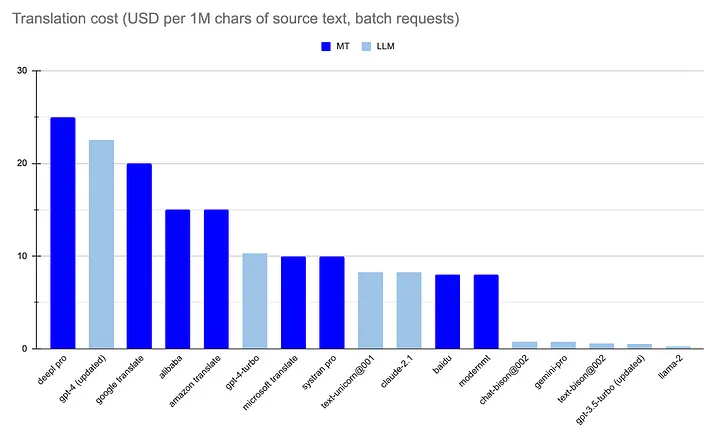
Translation cost GenAI vs MT (USD per 1M characters of source text).
General conclusion
- Generative AI models generally match the translation quality of top Machine Translation (MT) models, based on their semantic similarity to human translations. However, the performance drops significantly in specialized fields like Legal or Healthcare.
- The cost of using Language Learning Models (LLMs) for translation is either on par with or 20–25 times cheaper than standard MT models, as seen with Google’s LLMs and LLaMA-2.
- Despite this, modern LLMs are about 100 times slower than stock MT models.
- Generative AI models tend to add unnecessary explanations and reasoning to their output, a common error that can be corrected with automatic post-processing. Other issues are generally similar to those found in typical MT models.
- Exceptions include the LLaMA-2 model, which often hallucinates in multilingual tasks, and the Gemini Pro model, which frequently returns empty results due to safety filters.
- Google’s PALM 2 models (bison, unicorn) appear most promising for translation tasks. Their quality is comparable to other leading LLMs, but their cost is 20–25 times lower.
- However, we recommend sticking with MT models for now due to LLM’s slow speed. Generative AI should only be considered for translating large volumes of text, cross-dialect translation (e.g., between Spanish variants), and in-context translation (e.g., UI strings).

