

Last week, Intento Co-founder and CEO joined the GALA 2022: San Diego program to share his approach to analyzing post-editing efforts across enterprise localization activities. Keep reading for all the insights from the seminar, including the elements of a healthy localization and MTPE (machine translation post-editing) program, guidelines for diagnostics and analysis, source quality analysis, and recovery options.
• • •
Healthy Localization and MTPE
Here, we will focus on traditional MT use cases, which involve either adding or readily improving the machine translation elements in your localization tech stack. We’ll find out what it takes to benefit from adding MT to your workflow.
Bottlenecks
The trick is that great MTPE is not only about MT. There are many non-MT bottlenecks, such as misconfigured translation management systems, inconsistent translation memories, and the wrong contribution of translation memories to your project. Altogether, these may amount to a greater waste of resources outside of choosing the wrong MT. If you want to use your existing translation memories to train your MT, you’re going to want to solve these potential issues first.
Fuzzy match threshold
Another factor that may affect your efficiency is the fuzzy match TM/MT threshold. Typically you expect to take high fuzzy matches in context from TM (translation memories) then instead of low-fuzzy matches, you use machine translation. If this threshold is off in any direction, the translators are most likely overediting.
Some companies will only begin to pay attention to these details if the budget is affected. However, if translators are doing more than expected during the editing process, or have high uncertainty around editing, it will become apparent in the translation quality.
Pricing and discounts
If your machine translation is already in place, one thing you want to check is if the price is appropriate. You want to make sure that you are being charged fairly for MT post-editing compared to editing for translation memories and fuzzy matches. If you’re already applying post-editing, you’ll want to know where it’s falling short and where there’s room for improvement. Depending on that you’ll decide if you want to invest more of your budget in machine translation.
Translatable content
Finally, you’ll need to find out whether or not your content is right for machine translation. Perhaps in your case translators are mostly transcreate, and no amount of training on these transcreation strings will fix your process.
You need to consider all of these questions if you want to improve your machine translation process.
• • •
Guideline for diagnostics and analysis
Getting the Data
In a straightforward approach, you are dealing with source text (what was leveraged), match text, match type (ICE, exact match, fuzzy match, repetitions, MT), final text, and sometimes metadata (on the post-editing engine, for example).
Duplicates
Once you have the data, the first thing that you want to do is do a full analysis looking out for duplicates. Of course, you’re going to have many full duplicates across TM elements — that is expected. Other duplicates require more attention. If you see source-only TM duplicates, this may mean that there’s an inconsistency with how the TM is edited. This usually indicates issues with the TMS quality analysis process. Full MT duplicates are indicative of misconfigured repetitions, and you are going to end up paying for post-editing the same strings several times.
In the case of one client, they were paying 60% extra because of full MT duplicates, which you obviously want to avoid. Then there are source-only MT duplicates, meaning that you’re dealing with misconfigured repetitions with complications.

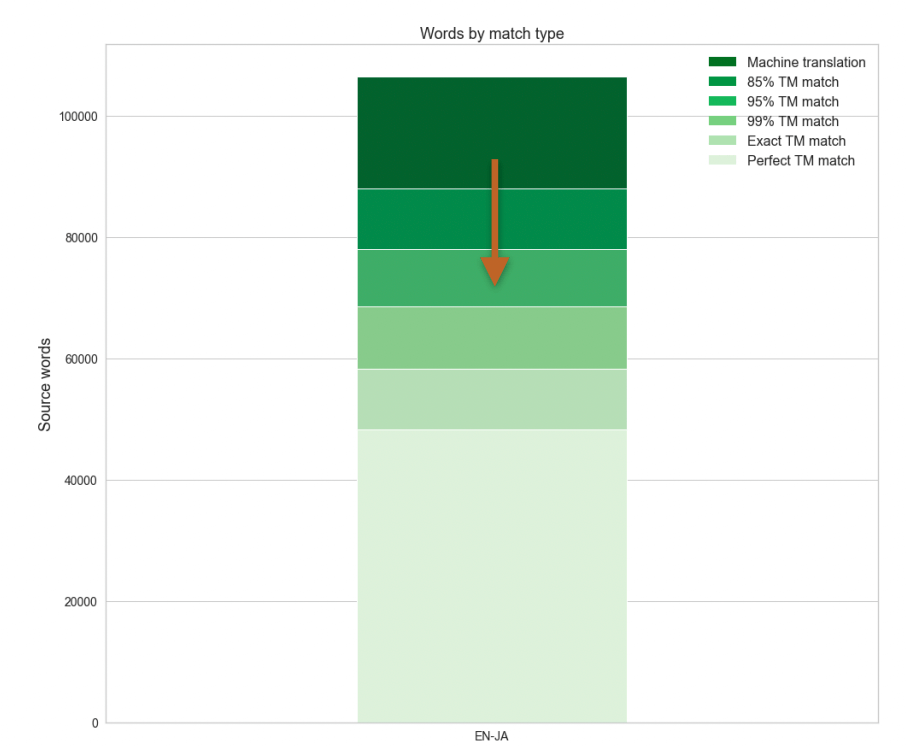
Match Types
After analyzing the duplicates, the next thing to do is look at the distribution of different words over different match types — both as a whole and by several smaller points of reference (segment length, project, etc.). This is critical when assessing the expected gains when MT is implemented. You should keep in mind that it is totally normal for the TM/MT threshold to rise.
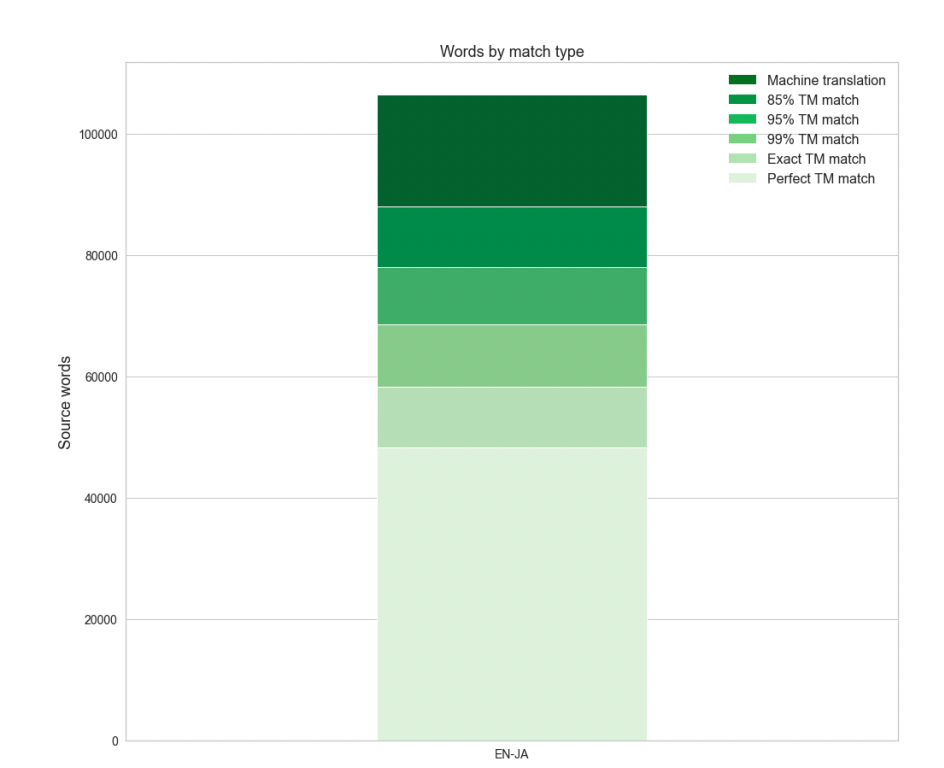
Post Editor Activity
A properly configured localization process enables organizations to increase the efficiency of their translation process — compared to translating texts over and over again from scratch. The main goal of an Intento check-up is to figure out what the level of efficiency is to start, and where you can go from there to improve. To do this, there needs to be a quantitative idea of how much effort is going into your translation activities. We’ll look at your post-editing activities as objectively as possible:

Looking at these factors as a whole across the board you will be able to gain a solid idea of what your level of effort is compared to translation from scratch.
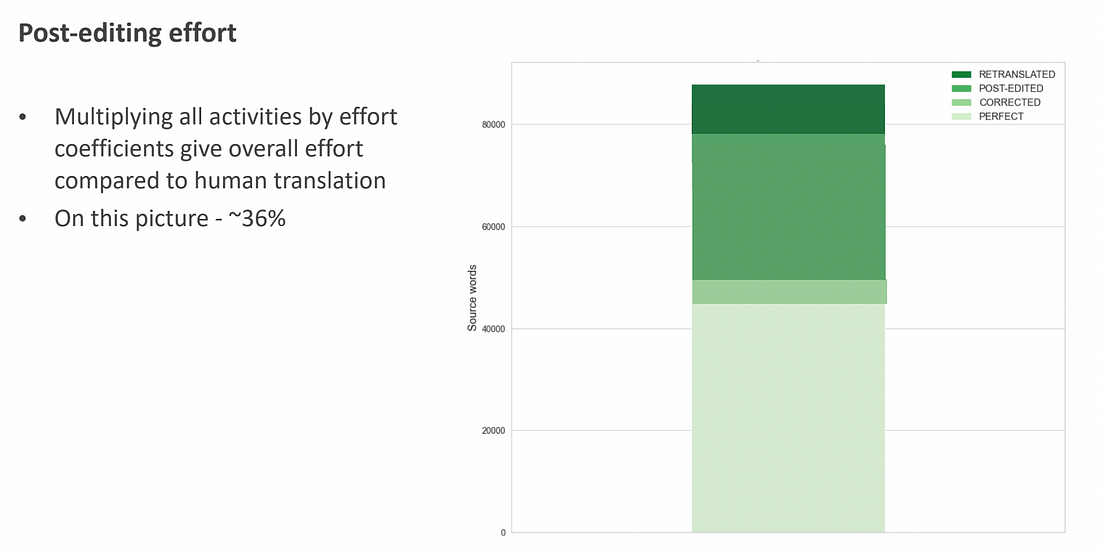
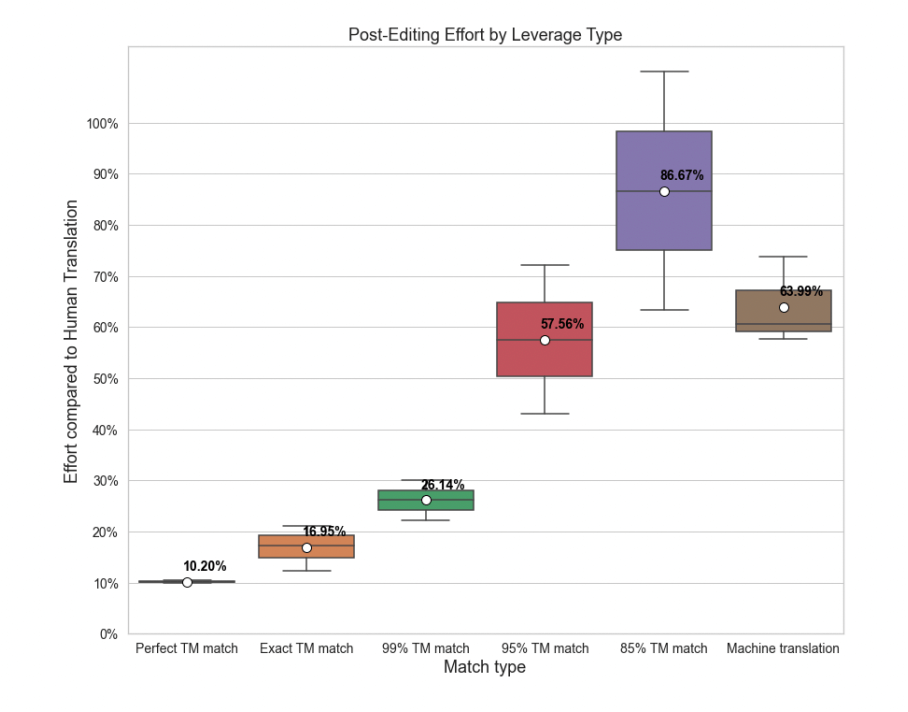
Specific TM Issues
If we see that some of the projects are outliers in terms of their TM match editing efforts, or we see an overall higher editing effort than expected, we can pull the top 100 segments by edit distance (TER) and analyze them. Typically, the problems you will see with TM have to do with improper labeling or sentence fragments in TM.
Specific MT Issues
We will then apply the same approach as for TM, however now looking for MT issues. We need to look at the segments with the biggest added distance. Once we find the largest issue according to this stat, we can apply the same solution to the remaining MT to prevent further issues.
One of the most prevalent issues that we see is DNT (‘do not translate’) — when something that should not be translated is mistakenly translated anyways. Our process automatically identifies them, and then builds a glossary of DNT terms that can be applied on top of the MT.
The opposite issue, false DNT, happens when something that should translate fails to do so. The remedy here is to further train your machine translation.
We also see issues with formats and numbers between different national or regional contexts. For example, the US and Japan have a big difference in how sizing is represented. These are not always automatically identifiable but can be fixed by MT training, especially if you’re using numbers in one language case, and words in another. Automated post-editing can also help in these situations.
There may be issues with encoding and text formatting. Because this will come up if the TMS is misconfigured, updating your TMS configuration can be useful.
For omissions, additions, mistranslations, and junk translations, you should either retrain the current MT engine or change engines altogether. With 40+ MT engines accessible through the Intento API, it’s often easier to change rather than retrain.
• • •
Source Quality and MTPE
Finally, there are source quality issues. Those are segments where MT produces reasonable and straightforward translations, but the post-editor changes it significantly. This effectively transcreates the translations further away from what they should be.
A familiar example here is using an American idiom that doesn’t translate well into a different cultural context. Look at ‘hitting it out of the park’ — in Japanese, this would be translated literally to a baseball reference, losing the actual meaning.
The trick is that you cannot really train machine translation on these segments. In some cases, training with such terms may actually ruin the batch, because the engine will begin to think that the problematic words don’t have their literal meaning.
You can use a couple of different strategies in these instances. One option is the alter the authoring guidelines so that your content is more translatable. This can be a tricky route because you’ll end up having to tailor your authoring guidelines for each specific national context. Of course, it is still a useful marketing tool to use American idioms for an American audience.
Another option is to create an international copy of the source material by first back translating the content, and then using that copy for further translations. This method has a proven impact on reducing the post-editing efforts.
The third option is to automate the transcreation through large language models like GPT-3 — but that can be explored further in another post.
• • •
Strategies to Improve MT
Based on the above issue areas, the following changes may be required in order to ultimately improve your MT.
TMS:
- Improve data storage and export methods
- Fix repetitions
- Adjust fuzzy TM/MT threshold
- Fix filters and encoding
- Fix project and TM attribution
LSP:
- Adjust MTPE price relative to TM fuzzies with a similar effort
- Review TM and MT discounts
TM:
- Remove inconsistent and outdates translations
MT:
- Add/fix DNT glossaries
- Retrain using clean MT
- Look into the possibility of switching engines
Source text:
- Build international copies
- Potential of large language models like GPT-3
• • •
Improvements
When these issue areas are addressed, your process is sure to improve. You’ll see the evidence in following check-ups later down the road. Fixing TM and TMS issues reduce both the amount and variability of PE efforts for TM leverage. The lower the variability — the lower the cost.
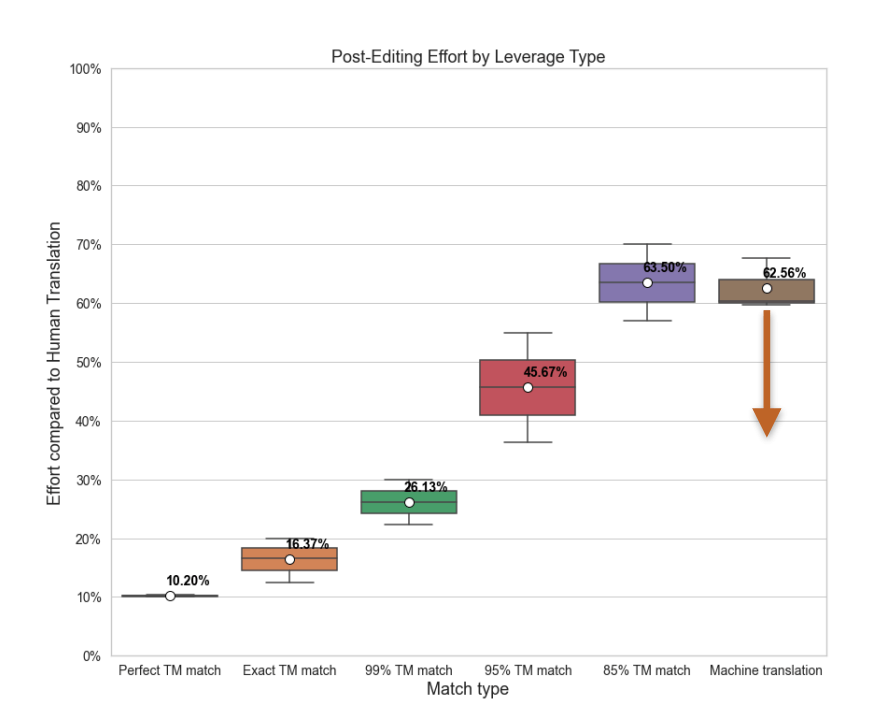
Improving your MT will reduce the MTPE efforts, bringing it below 95%. This will also help adjust the TM/MT threshold for post-editing efforts, adding more logic to how you think about post-editing pricing.
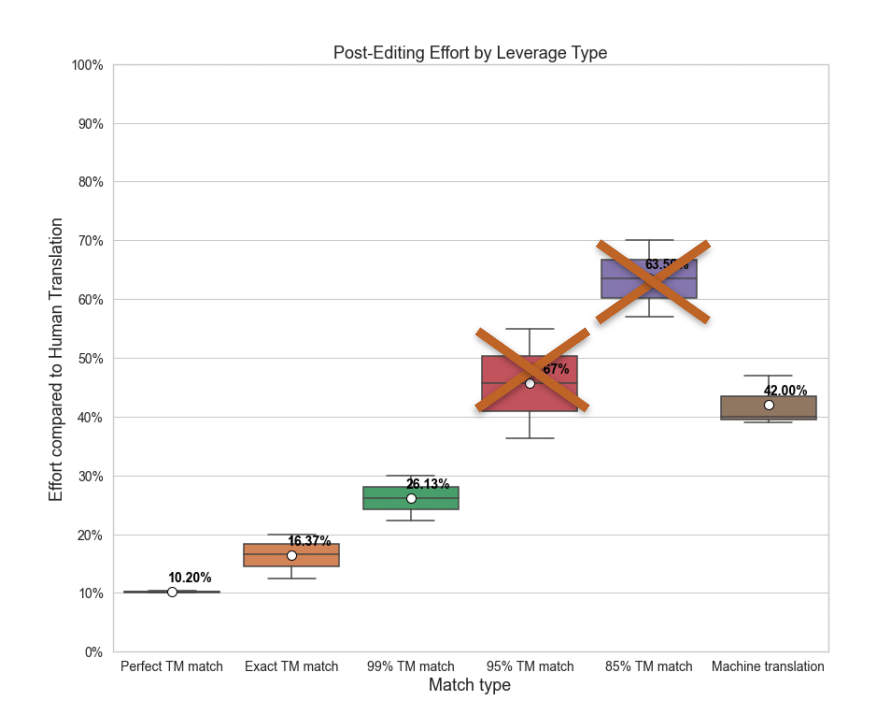
You are effectively sending more words to postediting and paying less at the same time. The overall translation effort will be reduced by at least 10% while translating 1.4x on the same budget.
• • •
Key takeaways
- Bottlenecks in the localization process can cause more issues than absent or inefficient MT.
- Many of these bottlenecks are overlooked by the majority of TMS and LSP vendors.
- Localization checkups will identify which issues you need to fix, estimating the room for improvement and potential gains through MT.
- Regular localization checkups will allow you to track how your MT and overall process continually improve.
To see how our localization checkup system runs on your data, reach out for a live demo here.


