

If you haven’t had time to follow all the news in the GenAI world, we prepared some important highlights of what happened during the last three months:
1. At the end of 2023, Google delivered many updates in its PaLM 2 model family: the largest text-unicorn@001, the updated text-bison@002 and chat-bison@002 models together with special versions supporting a larger context of 32k tokens. The newer models have much better quality and are very decently priced.
2. At the end of January 2024, OpenAI released an updated GPT-4 Turbo preview model named gpt-4-0125-preview. It supports a large context of 128k tokens, has an updated knowledge cutoff of December 2023, and includes a fix for the bug impacting non-English UTF-8 generations. The gpt-4-turbo-preview alias points to the new model already.
3. At the same time, OpenAI released an updated GPT-3.5 Turbo model called gpt-3.5-turbo-0125 with various improvements. Input prices for the new model are reduced by 50% to $0.0005 /1K tokens, and output prices are reduced by 25% to $0.0015 /1K tokens. If you use the gpt-3.5-turbo model alias, it points to the new model since today, February 16th.
4. New text embedding models, text-embedding-3-small and text-embedding-3-large, show stronger performance than the previous generation text-embedding-ada-002. Pricing for text-embedding-3-small has been reduced by 5X compared to the previous model. These new embedding models were trained with a clever technique called “Matryoshka Representation Learning”, which allows embeddings shortening without the embedding losing its concept-representing properties. It enables very flexible usage and trading off some accuracy in exchange for the smaller vector size. For example, that may help if your vector database only supports embeddings of a specific size.
5. The OpenAI’s free Moderation API, which allows developers to identify potentially harmful text, now has the text-moderation-007 model, the most robust OpenAI moderation model to date. The text-moderation-latest and text-moderation-stable aliases have been updated to point to it.
6. Yesterday, February 15, 2024, Google made several announcements regarding its new family of multimodal language models, Gemini. The Gemini 1.0 Pro model, designed to handle natural language tasks, multiturn text, and code chat, is now generally available (GA), so you can use this model in production. The largest and most capable model for highly complex tasks, Gemini 1.0 Ultra, is also generally available, however, via allowlist.
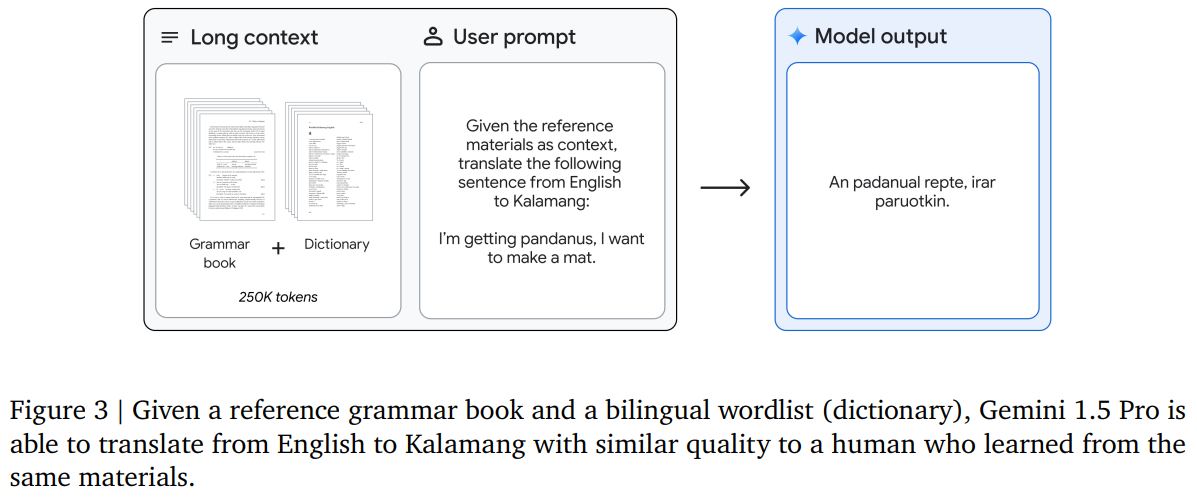
7. Google also introduced a new generation of Gemini models with Gemini 1.5 Pro, which delivers improved performance on a more efficient architecture. It performs at a similar level to Gemini 1.0 Ultra, Google’s largest model to date. 1.5 Pro has the longest context window of any large-scale foundation model yet. The standard version has a 128k token context window, but for a limited number of enterprise customers, it is extended to 1M tokens. This is enough to process a several hundred-page document with 700,000 words. The research version supports up to 10M tokens.
Among the beautiful examples of Gemini 1.5 capabilities in the report, we’d highlight the ability to learn to perform sentence-level translation between English and Kalamang (a low-resource language with fewer than 200 speakers) from instructional materials, a 500-page reference grammar, a 2000-entry bilingual wordlist, and a set of 400 additional parallel sentences (see the image in the post). The model learns to translate English to Kalamang at a similar level to a person learning from the same content.
Gemini 1.5 Pro is now in private preview.
8. As an alternative to large context, OpenAI is experimenting with memory for ChatGPT and GPTs. You can control what exactly ChatGPT remembers between chats. Hopefully, this ability will be available in a wider set of products and APIs later this year.
9. Last but not least, video-generation models are coming! OpenAI announced their text-to-video model Sora. It can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt. Access to Sora is very limited at the moment.
Stay tuned!

