

The landscape of machine translation is transforming dramatically with Large Language Models (LLMs) at the forefront. In our recent webinar, “Debunking myths about LLMs in Machine Translation,” Grigory Sapunov (CTO and Co-founder of Intento) and Andrzej Zydroń (CIO of XTM International) discussed the latest developments and addressed common misconceptions about costs, security, and implementation.
The rise of thinking models
DeepSeek’s breakthrough models (V3 for general chat and R1 for reasoning) showcase a new step in open model development. R1 is the first successful large-scale application of reinforcement learning for reasoning tasks in open models. There are commercial closed models using this technology, like OpenAI’s o1/o3 or Google’s Gemini 2.0 Flash Thinking, but among the open models, the largest reasoning model before R1 was QwQ by Alibaba Cloud. The DeepSeek models were trained mainly in English and Chinese, with some (unspecified) additions to other languages.
These “reasoning models” work differently from traditional approaches like GPT-4o, Gemini Pro, or Claude Sonnet. Instead of producing an immediate answer, they spend time on internal processing, breaking tasks into steps. As OpenAI has demonstrated with their o1/o3 model families, allowing the model to generate more tokens in its internal thinking significantly improves the quality of the final result.
If you are interested in technical details of DeepSeek V3 and R1 models, Grigory prepared a series of posts on the topic.
We at Intento are currently preparing a short research on DeepSeek’s translation capabilities. Stay tuned!
The cost structure of LLM translation
Traditional machine translation was simple—you paid for input characters, and you could easily calculate costs by counting characters in the original data. While custom models typically cost more than base models, pricing was straightforward. With LLMs, pricing becomes multidimensional:
Token-Based Complexity:
- You pay for tokens instead of characters. Tokens are typically frequent sub-word units, which may differ across different models.
- Non-Latin languages split into more tokens—while English typically has one or two tokens per word, languages like Chinese, Hindi, or those using Cyrillic or Greek alphabets may have more tokens per word, and some low-resource languages may even have more tokens than characters in the original sentence.
- Input and output tokens are priced differently—while you can calculate costs for data sent to the model, generation length is unpredictable. Setting token limits is possible but risks cutting sentences mid-way.
Context and Processing:
- New models with extended context (over 128,000 tokens) have different pricing before and after that limit, with higher rates after.
- You can save money with caching for repeated queries, but that adds more complexity to the pricing model.
- Batch processing offers cost optimization for large volumes through asynchronous processing.
- Internal “thinking time” for reasoning models adds costs because of usually hidden reasoning tokens.
- Multimodal LLMs (handling audio, images, and video) have separate pricing structures.
Open models may seem like a solution to the problem of cost optimization, but consider the Total cost of ownership (TCO), which includes expensive, scalable GPU infrastructure and labor costs for skilled engineers to implement and support the solution. Other factors, like a lack of SLAs and support or potential IP issues, may also matter.
Advanced technology behind LLM translation quality
LLMs use embeddings to understand meaning in translation. The model converts text into lists of numbers, enabling operations with words. If you take the embedding for “king,” subtract “man,” add “woman,” you get “queen.”
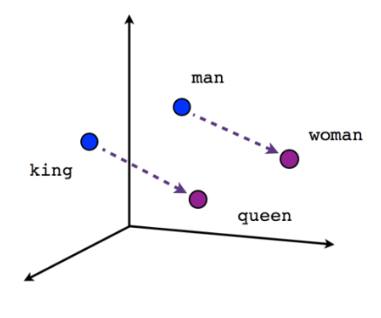 Image: Word embeddings visualization
Image: Word embeddings visualization
Source: University of Michigan, AI Lab (2018). “Word Embeddings and How They Vary.”
Photo credit: Jaron Collis on Quora
Similarly, if you take “woof woof” (the English sound for dog barking), subtract “dog” and add “cat,” you get “meow.” This shows how models understand relationships between words mathematically, going beyond simple word matching. This principle helps find and apply relevant matches from past translations, making results more accurate and consistent. This way, with Retrieval Augmented Generation (RAG), LLMs can achieve human-quality translations by learning from context and previous translations.
Translation quality isn’t just about accurate words—it’s about meeting all your enterprise requirements. Single LLM calls are usually not enough to incorporate all these requirements.
While it may be technically possible to put everything into a single huge prompt, that will likely degrade the quality of the outcome because models do not usually work perfectly with longer contexts, and different requirements may interfere with each other. Moreover, different requirements may be owned by different parts of the organization, making change management a big issue. Multiple AI agents working together to handle this complexity—from terminology consistency and style guides to technical accuracy and cultural adaptation—provide a viable alternative. Each agent specializes in specific aspects, making it easier to maintain quality standards.
Keeping your content safe with LLM translation
Commercial LLM providers have addressed data security concerns. Most major vendors (like OpenAI, Anthropic, and Google) explicitly state they don’t use customer data to train their models. They offer:
- Clear data usage policies (though terms should be carefully reviewed)
- Flexible data retention settings (like OpenAI’s 30-day retention with opt-out options and a zero data retention agreement)
- Protection against IP issues through indemnification
- Private cloud options for industries requiring enhanced security
Translation technology that keeps getting smarter
Translation technology has taken a significant step forward with LLMs. The agentic approach—where different AI agents specialize in specific requirements—makes complex translation tasks more manageable. Teams can now work effectively with full texts, implement glossaries, and leverage translation memories in ways impossible with traditional MT.
The technology now understands meaning, not just words. Through embeddings and vector stores, systems can recognize when content means the same thing, even when written differently. This smarter approach to matching content improves translation quality and efficiency, paving the way for even more advances as the technology develops.
Ready to explore how LLMs can transform your translation workflow? Book a demo.


