

A crucial part in using Machine Translation (MT) is the evaluation process. The BLEU score is a commonly used metric for this step. It has significantly impacted MT field by removing the bottleneck in the evaluation, which was done by human and could take months. Although there are still some problems with the BLEU metric:
- BLEU is a parameterized metric which values can vary wildly with changes to these parameters (e.g., number of references, the maximum n-gram length, the computation of the length penalty, smoothing applied to 0-count n-grams).
- Different preprocessing of the reference cannot be compared. This is because BLEU is a precision metric, and changing the reference processing changes the set of n-grams against which system n-gram precision is computed. Preprocessing includes input text modifications such as normalization (e.g., collapsing punctuation, removing special characters), tokenization (e.g., splitting off punctuation), compound splitting, lowercasing, and so on.
- Benchmarks set by well-cited papers and vendors use different BLEU configurations. Which one was used is often difficult to determine. These variations can lead to differences as high as 1.8 points between commonly used configurations. Table 1 shows effect of BLEU scores with different reference tokenizations.
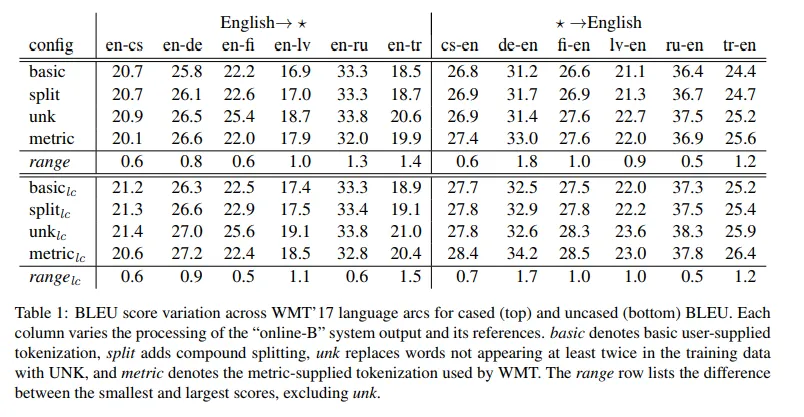
From Matt Post, “A Call for Clarity in Reporting BLEU Scores”
All these problems together make it impossible to compare various systems scored by different BLEU’s configurations and preprocessing steps.
Matt Post from Amazon Research published a paper on this problem, suggesting machine translation researchers settle upon the BLEU scheme used by the annual Conference on Machine Translation (WMT), which does not allow for user-supplied reference processing. To facilitate this he additionally provides a new tool, SacreBLEU. The main advantage of SacreBLEU is that it applies its own metric-internal preprocessing, producing the same values as WMT.
You can calculate SacreBLEU through our Scores API. If you don’t have an API key you have to register first and then you will find it in your dashboard.
Let’s get to business. Here is a simple example of a request to Score API:
curl -X POST -H 'apikey: YOUR_API_KEY' 'https://api.inten.to/evaluate/score' -d '{
"data": {
"items": [
"Ten of the last eleven national surveys showed Donald Trump leading in the two-digit range, and some begin to seriously wonder what it means for the chances of nominating the real estate moguls.",
"The two wanted to talk about the implementation of the international agreement and about Tehran'\''s destabilizing measures in the Middle East."
],
"reference": [
"Ten of the last 11 national polls have shown Donald Trump'\''s lead at double digits, and some are starting to ask seriously what it means for the real estate mogul'\''s nomination chances.",
"The two wanted to talk about the implementation of the international agreement and about Teheran'\''s destabilizing activities in the Middle East."
],
"lang": "en"
},
"scores": [
{
"name": "bleu-corpus",
"ignore_errors": true
},
{
"name": "sacrebleu",
"ignore_errors": true
}
],
"itemize": false,
"async": true
}'
We’re comparing two sentences in this request. Items key is a machine-translated text and reference key is a ground truth text. For comparison, we selected two metrics: bleu-corpus and sacrebleu. Scores API is an asynchronous service, so after sending request we get an operation’s id, which we will use later to retrieve the result.
{"id": "360b4b50-d530–4112–8c93–08dc84bf4227"}
For retrieving scores, we send a GET request to the operations resource:
curl -H 'apikey: YOUR_API_KEY' https://api.inten.to/operations/360b4b50-d530-4112-8c93-08dc84bf4227
Finally here’s a response:
{
"id": "360b4b50-d530–4112–8c93–08dc84bf4227",
"done": true,
"response": {
"results": {
"scores": [
{
"value": 45.18,
"name": "sacrebleu"
},
{
"value": 46.48,
"name": "bleu-corpus"
}
]
}
}
}
As we can see the difference between SacreBLEU and BLEU-corpus is 46,48–45,18 = 1,3.
While BLEU is the most popular metric, others may better correlate with human translation for specific cases. For example, hLEPOR provides better results for morphologically complex languages (such as Czech and German), TER is considered better correlated with the post-editing effort, while RIBES works better for Asian languages.
With the Score API, you can calculate other MT scores such as bleu-sentence, ribes, ter, hlepor. While the API is in beta, you can use it for free, even with the sandbox key you get right after registered at Intento.


