

In the fast-paced world of localization, staying ahead means constantly researching and testing new metrics to assess machine translation quality.
At Intento, we use a range of reference-based metrics to evaluate machine translation (MT) quality, from fast and affordable scores like COMET to complex and time-intensive LLM-based metrics for Multidimensional Quality Metrics (MQM) and Business-Critical Errors (BCE) analysis. We’re always on the lookout for new metrics that can fill the space between these two methods.
We’re always on the lookout for innovative approaches that strike the right balance between efficiency, cost-effectiveness, accuracy, and interpretability. In this article, we dive into the results of the WMT23 Metrics Shared Task and evaluate five standout metrics: MaTESe, MetricX-23, GEMBA-MQM, XCOMET-XL, and CometKiwi-XL. Our aim? To identify metrics that can enhance our commercial evaluations and annual Machine Translation Report.
Key takeaways:
- While promising, most metrics we evaluated had limitations that prevented us from using them in production, such as restricted language pairs, interpretability issues, slow speeds, or high costs.
- CometKiwi-XL emerged as a strong contender for our research purposes, offering quick and effective reference-free translation evaluations under a non-commercial license.
- The machine translation evaluation landscape is constantly evolving, and staying informed about the latest developments is crucial for making data-driven decisions in your localization strategy.
Read on to discover the insights we gleaned from our in-depth analysis and how these cutting-edge metrics could shape the future of translation quality assessment.
Datasets
The WMT23 Metrics Shared Task paper evaluates three language pairs: Chinese to English and Hebrew to English at the sentence level and English to German at the paragraph level. For our research, we used our internal datasets to test metrics’ ability to identify and penalize specific translation errors. We focused on these language pairs:
- English>German
- English>Spanish
- English>French
- English>Japanese
Each dataset has 500 segments, including the source text, a reference translation, and machine translation. Professional translators produced the test set reference translations, while a leading MT provider generated the machine translations.
Exploring New Metrics
MaTESe is a non-commercial metric that identifies and categorizes errors in a candidate translation. The metric can be used even if the reference translations are not available. The paper can be accessed at https://aclanthology.org/2022.wmt-1.51/, and the code implementation is available at https://github.com/SapienzaNLP/MaTESe/tree/main.
MetricX-23 and its variations are metrics trained to predict a score representing the quality of a given translation. HuggingFace offers 6 models that differ in their number of parameters and whether they are reference-based or reference-free. The paper can be accessed at https://aclanthology.org/2023.wmt-1.63.pdf, and the code implementation is available at https://github.com/google-research/metricx.
GEMBA-MQM adopts few-shot learning with OpenAI’s GPT-4 model, prompting the model to identify issues in a candidate translation. The paper can be accessed at https://arxiv.org/pdf/2310.13988.pdf, and the code implementation is available at https://github.com/MicrosoftTranslator/GEMBA/tree/main.
XCOMET-XL, a new COMET model, identifies error spans in sentences and generates an overall quality score based on the issues found. XCOMET-XL can be used with or without reference translations. The paper can be accessed at https://arxiv.org/pdf/2310.10482.pdf, and the code implementation is available at https://huggingface.co/Unbabel/XCOMET-XL. The metric flags errors in a translation, if present, specifying their location in the candidate translation and severity level based on the MQM system (minor, major, critical). However, the metric is unable to categorize these errors into groups.
CometKiwi-XL is a reference-free metric from the family of COMET models that predicts a score representing the quality of a given translation. The paper can be accessed at https://arxiv.org/pdf/2309.11925.pdf, and the code implementation is available at https://huggingface.co/Unbabel/wmt23-cometkiwi-da-xl.
Evaluation approach
Our main goal when researching MT metrics is to identify metrics that 1) can be used in commercial evaluations and 2) can be used in the research for our Annual MT Report to add even more accuracy to the analysis. Our aim is to assess whether the new metrics would be fast and cost-effective in these 2 scenarios.
For that, we evaluated the correlation of these new metrics with the following 2 metrics:
- COMET is a quick, affordable reference-based metric that produces translation quality scores closely aligned with human evaluations. However, COMET’s simplicity and speed may come at the cost of assessment depth and complexity.
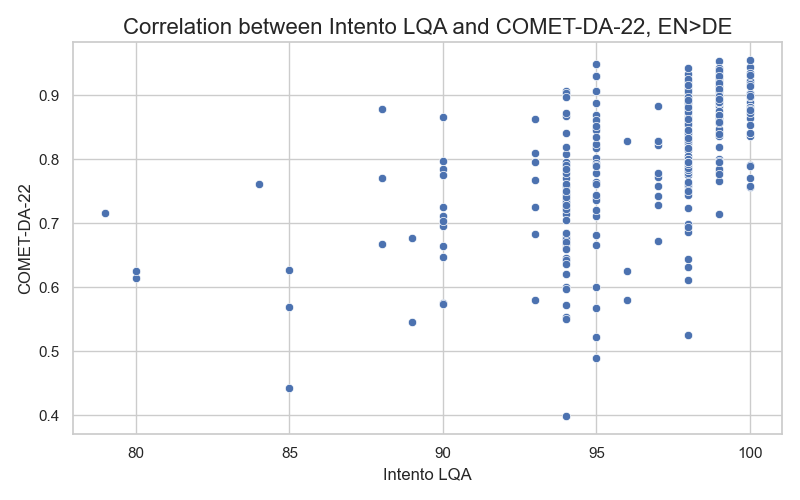
- Our proprietary GenAI-based metric, Intento LQA, has an 80% correlation with human judgment. It uses an MQM classification of issues in candidate translations. While less efficient than COMET in terms of time and cost, it provides a detailed evaluation of each candidate translation, including evaluation scores, a list of identified issues, and comments on each issue. Our metric has a moderate correlation with COMET scores, as shown in the correlation plot for English to German translations below:
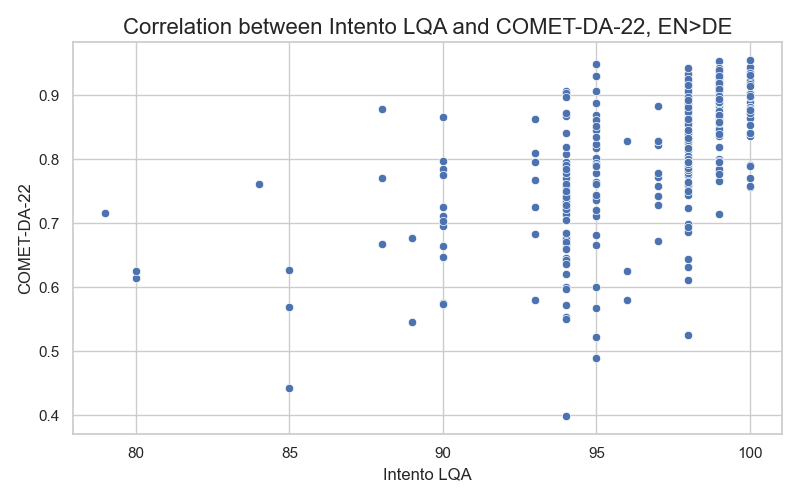
In our study, we aim to strike a balance between efficiency, cost-effectiveness, accuracy, and interpretability.
To evaluate each new metric, we grouped the translations based on the metric’s scores and their correlation with our Intento LQA metric and COMET semantic similarity scores. We then sampled from each group. Next, we performed our own human analysis to assess score interpretability and the metric’s ability to correctly identify translation issues.
MaTESe
The authors of MATESE, a machine translation evaluation metric, admit in their paper that their approach has weak generalization abilities. The metric also has significant language restrictions because it was only trained on English to German, Chinese to English, and English to Russian data. This is a major drawback, considering that many metrics in the WMT23 metrics task results are multilingual.
Given the wide range of language pairs in our Annual MT Report and commercial evaluations, we need a metric that covers many languages. So, for our purposes, we won’t move forward with analyzing this metric.
MetricX-23
We tested the largest model, MetricX-23-XXL, using both reference-based and reference-free methods. We found that the scores were difficult to interpret consistently within the same language pair. For instance, some translations received high or even perfect error scores from MetricX-23, while COMET semantic similarity scores indicated that the translations were of high quality. In fact, these translations either were of high quality based on human analysis or matched the reference translations exactly. Here are a few examples of English-to-German translations:
Similar patterns emerged when analyzing the correlation with our Intento LQA metric: the correlation coefficient is nearly zero, and several high-quality candidate translations have high MetricX error scores but score well on our metric. Below are the correlation plots for the English>German and English>Spanish datasets (for both reference-free and reference-based models):
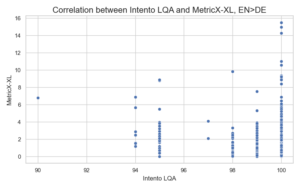
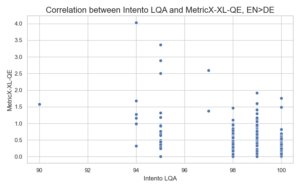
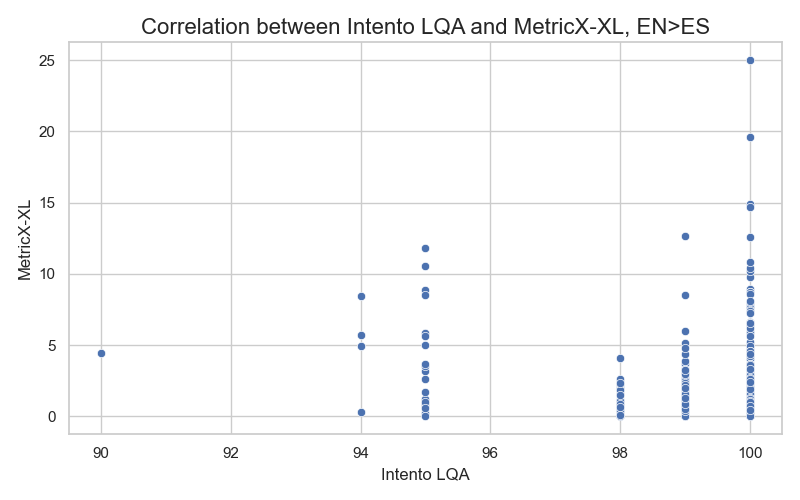
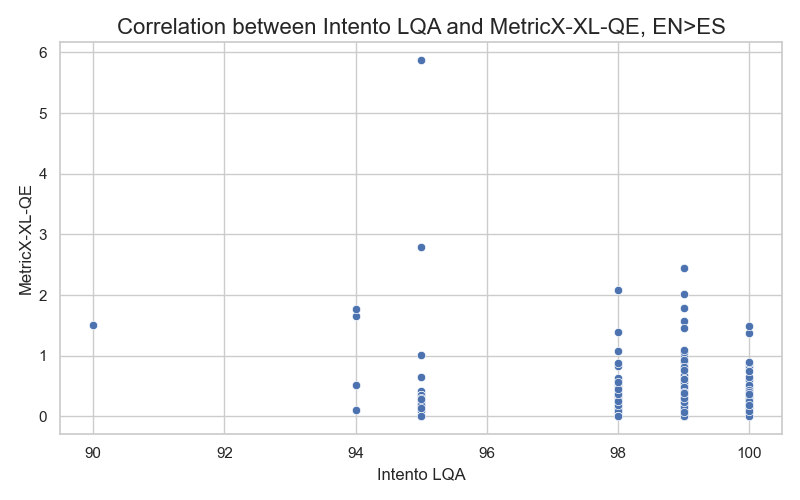
Another challenge in using this metric for production is its slow speed. In our experiments, we used an AWS g4dn.4xlarge instance with a single GPU for processing. Regardless of the language pair, evaluating one segment takes about 1.5 seconds on average. In comparison, COMET can evaluate a segment in around 0.05 seconds.
GEMBA-MQM
We compared the performance of this metric with Intento LQA, which is based on the same model and MQM classification but uses zero-shot prompting with language pair specification in the system message. For all language pairs, we observed a moderate positive correlation (around 0.5-0.6) between GEMBA-MQM and our Intento LQA metric, while the correlation between GEBA-MQM and COMET was slightly lower (around 0.5). There were a significant number of segments with extremely low GEMBA-MQM scores and high scores for our metric. Additionally, we noticed data points on the correlation plot where GEBA-MQM scores were at their lowest, while COMET scores varied between 0.5 and 0.9. Here’s a correlation plot for the English>German dataset:
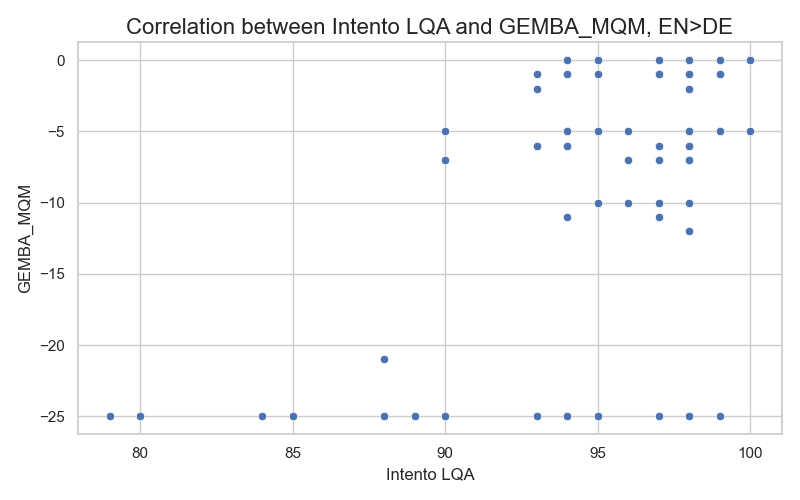
Sometimes GEMBA-MQM assigns the lowest scores possible if there is only 1 critical error (e.g. a verb or a letter was omitted), while the rest of the translation is of good quality. Below are a couple of examples for English>Spanish and English>German:
We chose a subset of the original data for detailed evaluation. Our linguists assessed each model’s ability to detect translation issues, labeling each as correct, incorrect, or partially correct, and provided detailed comments. We compared the number of each label per model, which showed our model performed better overall. The results for English to German and English to Spanish are below:
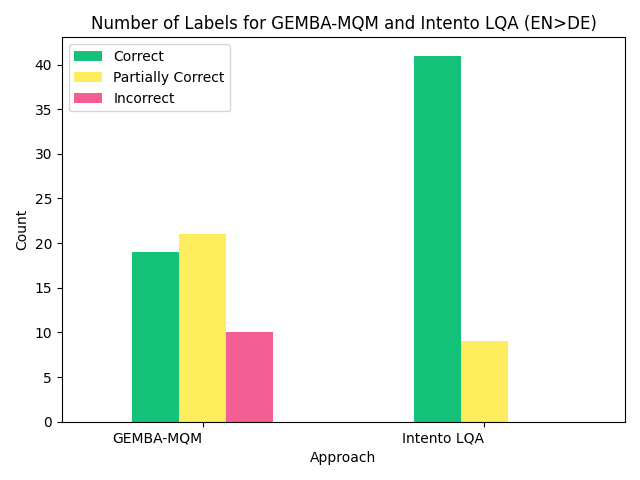
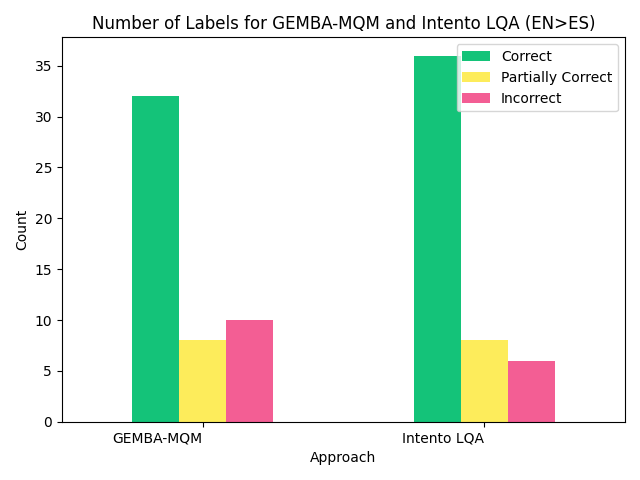
Most incorrect and partially correct assessments for both models result from GPT-4 identifying nonexistent issues while overlooking minor problems in the translation.
Our analysis suggests the metric shows promise but is not cost-effective due to its few-shot approach. The average evaluation time per segment is about 1.7 seconds, indicating suboptimal time efficiency. Moreover, the metric requires frequent updates to keep pace with OpenAI’s constantly evolving models, introducing unpredictability in the output results.
XCOMET-XL
The model penalizes literal translations, grammatical errors, and other major issues, but it appears to perform inconsistently. Some scores are difficult to interpret, especially when evaluating candidate translations of varying quality within a single language pair. The metric sometimes assigns higher scores to lower-quality translations and lower scores to higher-quality ones. Scores are more challenging to interpret when the model only has access to the source and candidate translation. Here are a few examples of English-to-Spanish translations:
The correlation coefficient between XCOMET-XL and our metric is moderately positive (0.4-0.6 range) across different language pairs. Both metrics appropriately penalize translations with major to critical problems. Correlation plots for English-to-French and English-to-Japanese datasets are shown below:
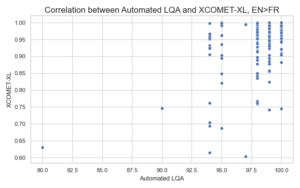
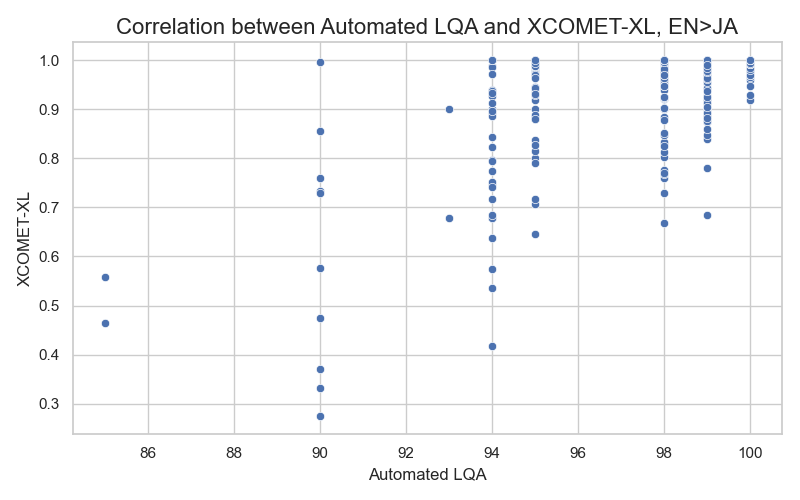
We see many translations that score high on Intento LQA but low on XCOMET-XL. These translations are actually good quality with only minor issues, if any. Here are a couple of English-to-Spanish examples:
Evaluating a single segment takes around 0.2 seconds on average, which is much faster than GEMBA-MQM.
CometKiwi-XL
The metric heavily penalizes translations that are too literal, especially when the source text contains idioms. Although CometKiwi-XL has a weak correlation (~0.3) with our metric, it’s better at penalizing overly literal translations of idioms than our metric is.
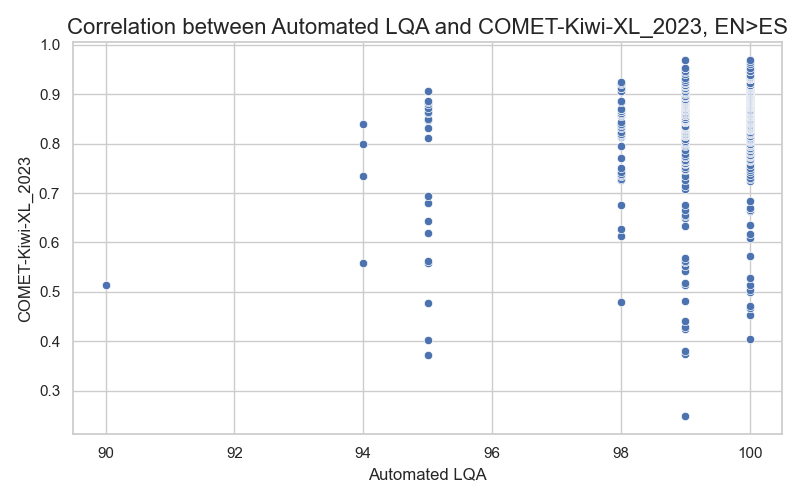
As anticipated, CometKiwi-XL gives low scores to translations with grammar problems, missing information, and other significant issues. The scores are also simple to interpret, and evaluating one segment takes only about 0.1-0.2 seconds on average, which is much faster than GEMBA-MQM. This metric is perfect for research since it is licensed under cc-by-nc-sa-4.0, which prohibits commercial use due to its non-commercial restriction.
Conclusions
While all metrics discussed in the article showed promise in the Metrics Shared Task, we chose not to use any of them in production. Factors like limited language pairs (MaTESe), interpretability issues, slow evaluation speeds (MetricX-23), and the need for frequent updates and high costs (GEMBA-MQM) significantly influenced our decision.
However, we see great potential in CometKiwi-XL as a metric for our research, as it’s non-commercial (license: cc-by-nc-sa-4.0). The metric offers a quick and effective way to evaluate reference-free translations and identify errors within them.
We’re thrilled about the ongoing development of new metrics in translation evaluation, and we look forward to testing and possibly implementing cutting-edge metrics in the future!


