Imagine having a localization tool that not only translates your content without mistakes but also adapts to your specific terminology and style in real-time. This is no longer a dream with the advent of Retrieval Augmented Generation (RAG) and Large Language Models (LLMs). In this article, we’ll explore how RAG is transforming the localization landscape and how you can leverage it for your projects.
Why do you need RAG?
Retrieval-Augmented Generation (RAG) is a cutting-edge technique that enhances the quality of Large Language Model (LLM) responses by retrieving relevant data for a given question or task and including it as context in the prompt. RAG addresses several common issues with LLMs:
Incorporating fresh data
RAG allows you to incorporate fresh data that came after fine-tuning your LLM, overcoming the “knowledge cutoff date” limitation. This is crucial when the most advanced LLMs, like GPT-4o or Claude 3 Opus, don’t offer fine-tuning options immediately after release. RAG provides an effective and cost-efficient customization solution in such cases.
Including additional context
RAG helps when you’ve trained an LLM on your translation memories and want to include additional data, such as glossaries, style guide rules, or metadata related to a specific request.
Helps LLMs focus
LLMs can easily be sidetracked by irrelevant information in a prompt, leading to incorrect answers. Providing a full glossary with every translation request can be expensive and may decrease quality. RAG helps LLMs focus by offering only concise, relevant information and filtering out irrelevant data.
Bypasses context length limitations
LLMs typically have limited context lengths, restricting the amount of input text. While earlier models like GPT-2 and 3 had context sizes of 2-4k tokens, the latest GPT-4 Turbo versions allow 128k contexts, and experimental models like Google Gemini 1.5 Pro have even larger contexts of 1M tokens. If your current model has a limited context that can’t accommodate everything you want, RAG helps you select the most important examples, bypassing model limitations.
How does RAG work?
Here’s how RAG works: You have a request for an LLM to complete a task. Depending on the request, you search an external database or storage for relevant text blocks and include them in the prompt given to the LLM. The prompt contains basic instructions on the task, examples for few-shot in-context learning, and additional factual information to help the LLM provide a correct answer.
For instance, let’s say you’re localizing a technical manual using an LLM that cannot be fine-tuned on your data. You have a translation memory (TM) and a glossary specific to the project. With RAG, you can build a translation prompt that incorporates similar translations from your TM, glossary terms that appear in the source text, and their desired translations. To use RAG, you store your TM and glossary in a database, so that for each translation request, they can be queried for similar fuzzy translations and glossary terms, which are then inserted into the prompt.
Translators are no strangers to working with historical data and context. Translation memories and glossaries are extensive, and CAT tools have features to retrieve relevant glossary and TM parts for the translated segment. This is essentially retrieval augmented generation, with the human translator acting as the generator.
Some TMS and MT systems, such as Systran NFA and memoQ AGT, are already experimenting with using RAG for TM entries. The key challenge is that translation memories may contain noise, inconsistencies, or outdated translations. We recommend thoroughly cleaning TMs before using them for RAG.
Glossary application with RAG
Glossaries and custom terminology are another common use case for RAG-like technology. Before LLMs, MT could use glossaries with search and replace. At Intento, we use a similar approach to implement simple glossaries on top of any MT system that supports HTML tags.
Given a segment to translate with a desired glossary, we quickly search it for any glossary items. If anything is found, they are marked with markup (e.g., HTML tags). Then, we translate it with the chosen model and look for the markup in the output. Finally, we replace all the translated elements inside the found markup with the corresponding glossary items.
This is a basic case of RAG without using LLMs. It works well for proper nouns, acronyms, and DNT (Do Not Translate terms), but not for common words, as they need to be substituted in the proper grammatical form.
However, our customers requested more flexible glossary support, as some of the existing MT systems that support morphological glossaries often come with reduced translation quality. This is where LLMs and RAG come in.
Augmenting LLM for translation
With LLMs, the translation landscape changes significantly. Modern top-tier LLMs can perform translation on par with the latest MT systems.
Glossaries remain largely the same when an LLM replaces MT, but search & replace is no longer needed. Glossaries can be added directly to the prompt.
To translate a segment with an LLM and a glossary, search the segment for glossary items just like with older MT (this is the retrieval procedure for RAG). If glossary terms are found in the input, take only the relevant part of the glossary (to avoid distracting the LLM) and add it to the prompt. The prompt now has the source text, relevant glossary section, and instructions on translating the text using this extra information. The LLM then translates, ideally incorporating the glossary items in their correct grammatical forms.
How to use RAG without building it yourself?
Ready to experience the power of RAG for your localization projects? With Intento Language Hub, you can easily use RAG for glossaries with any LLM. Our platform seamlessly integrates with your existing workflows, allowing you to leverage the latest advancements in AI and LLM technology without any hassle.
Here’s a short walk-through:
1. Create your glossary using Intento’s Glossary Management system and choose a suitable name. Note that LLMs currently ignore case sensitivity.
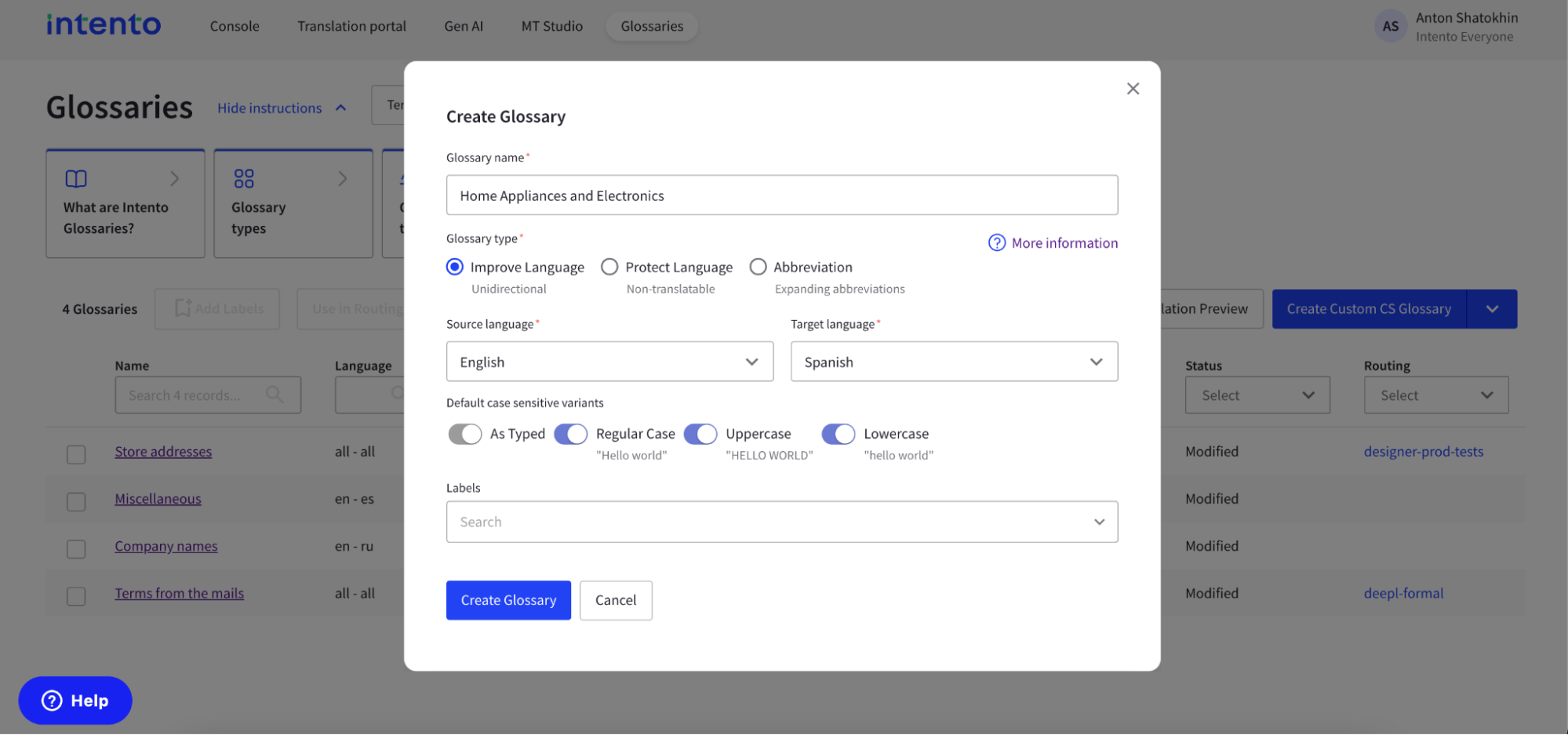
And add new term to the glossary:
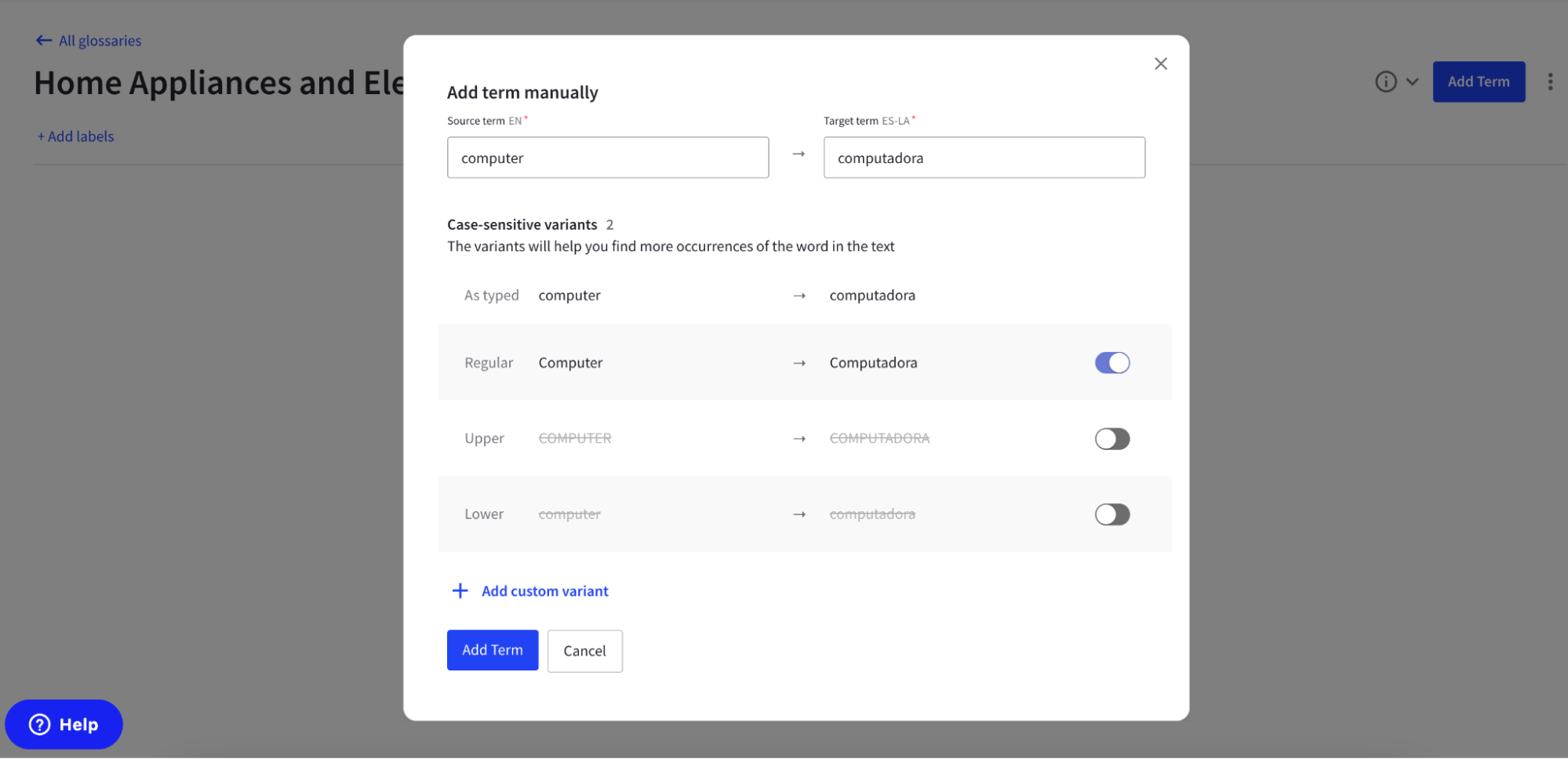
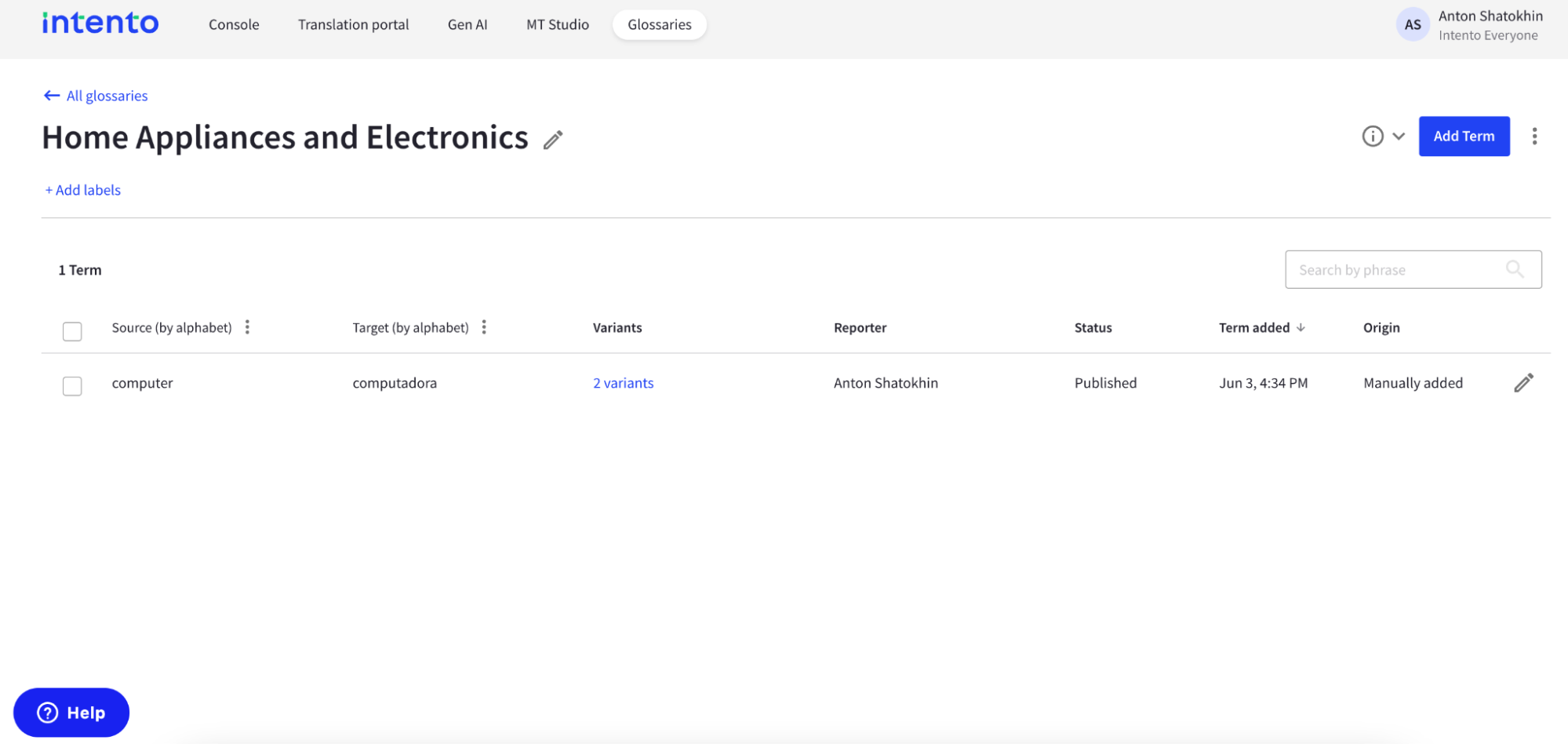
2. Set up a translation routing in Intento Language Hub, and select one of the available LLMs with standard translation prompts. We currently support applying glossary with OpenAI (GPT-3.5, GPT-4 model families), Google (PaLM2 and Gemini model family), Anthropic (Claude model family).
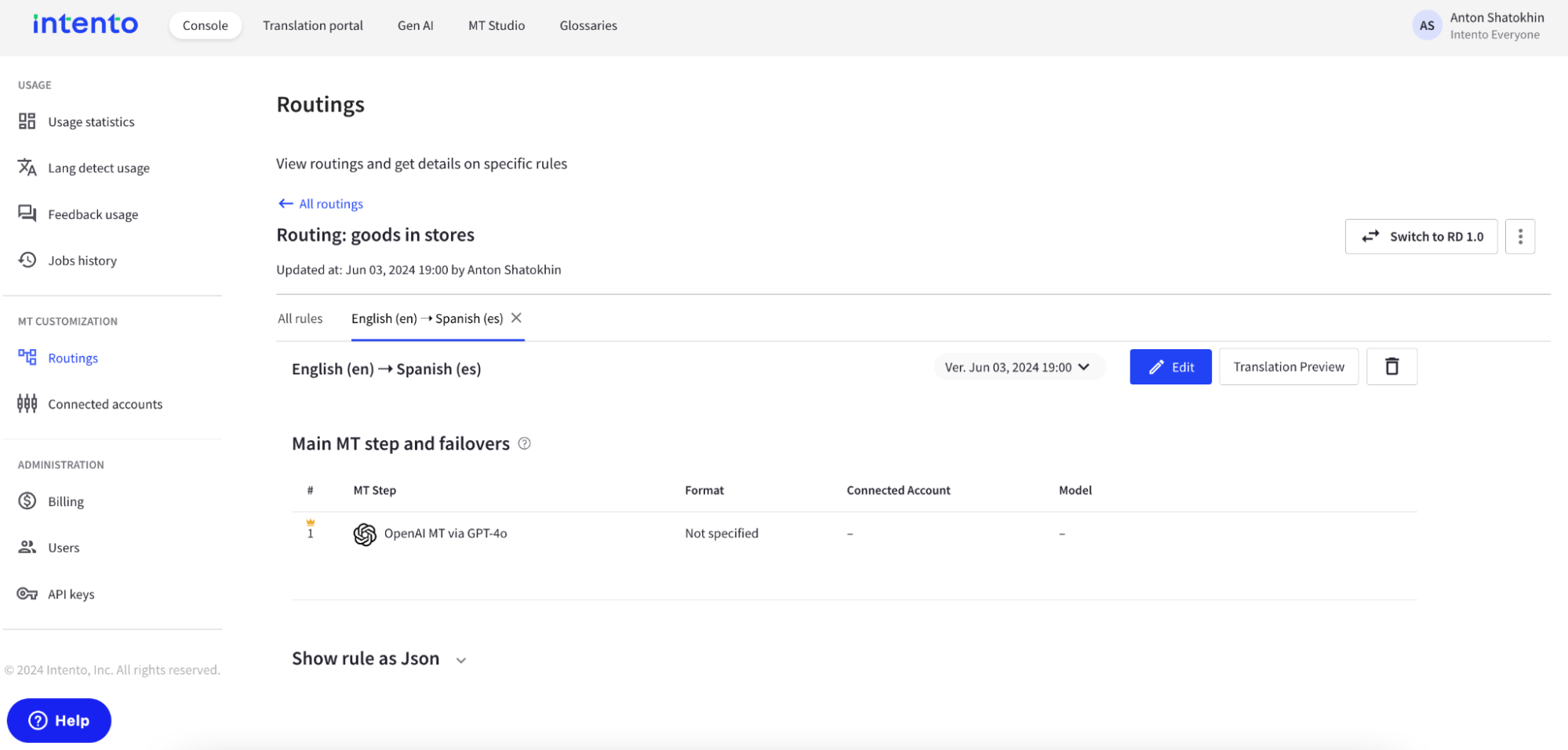
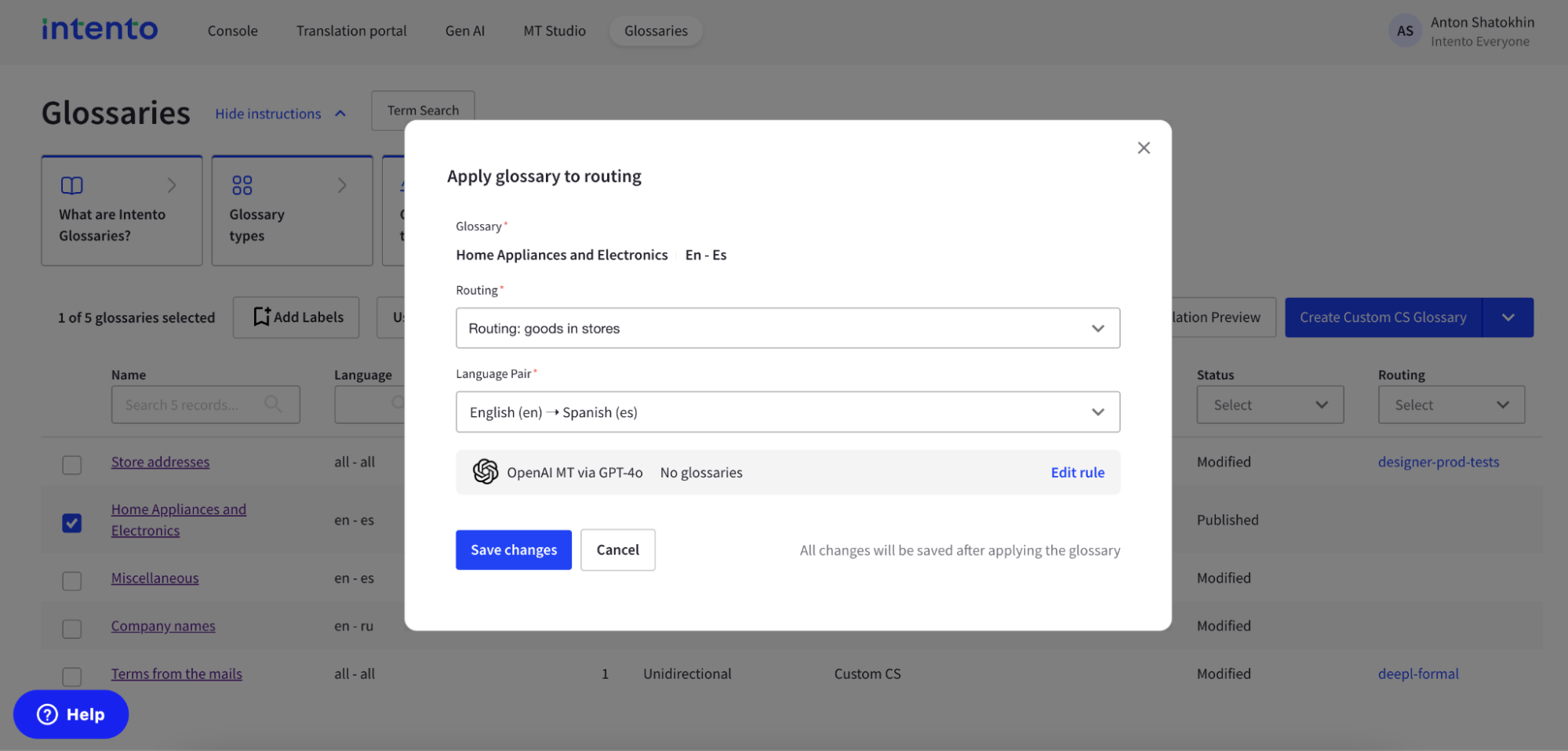
3. Add your glossary to the routing for the chosen LLM.
No glossary:
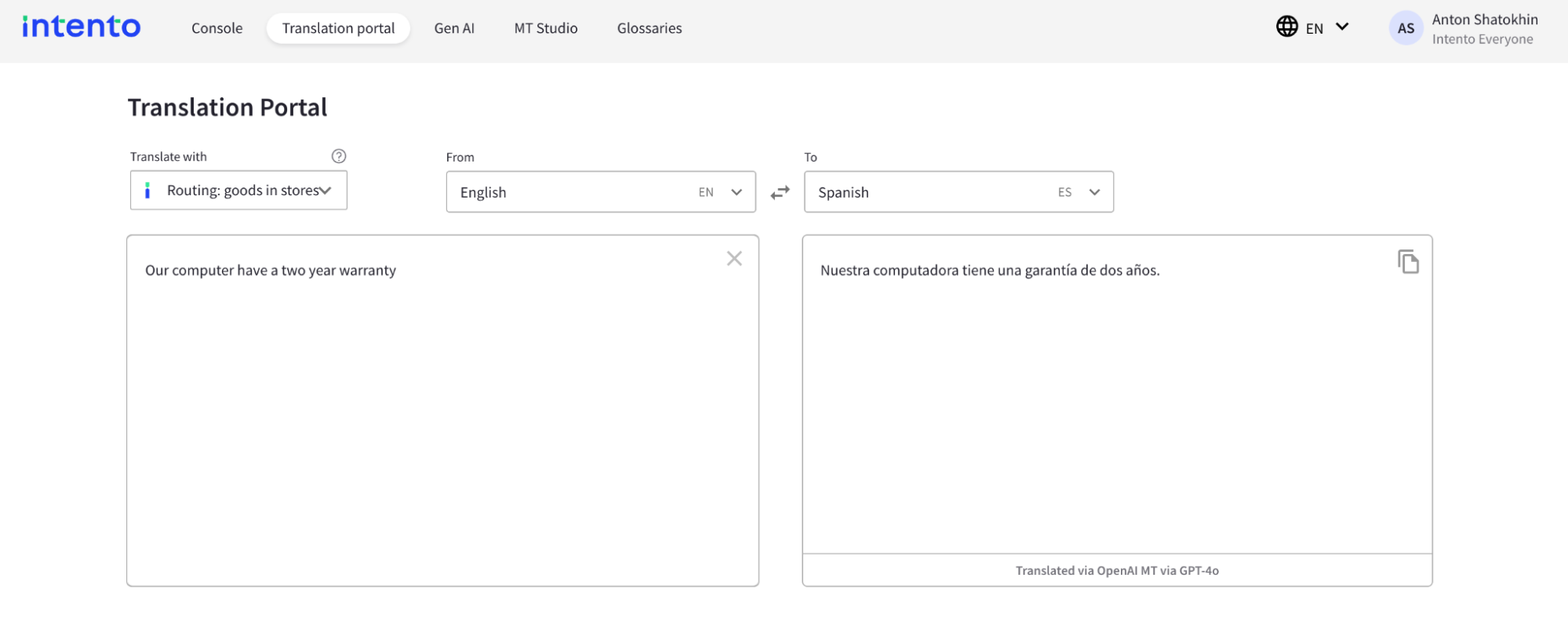
4. Verify that it works, for instance, in the Intento Translation Portal.
Without glossary
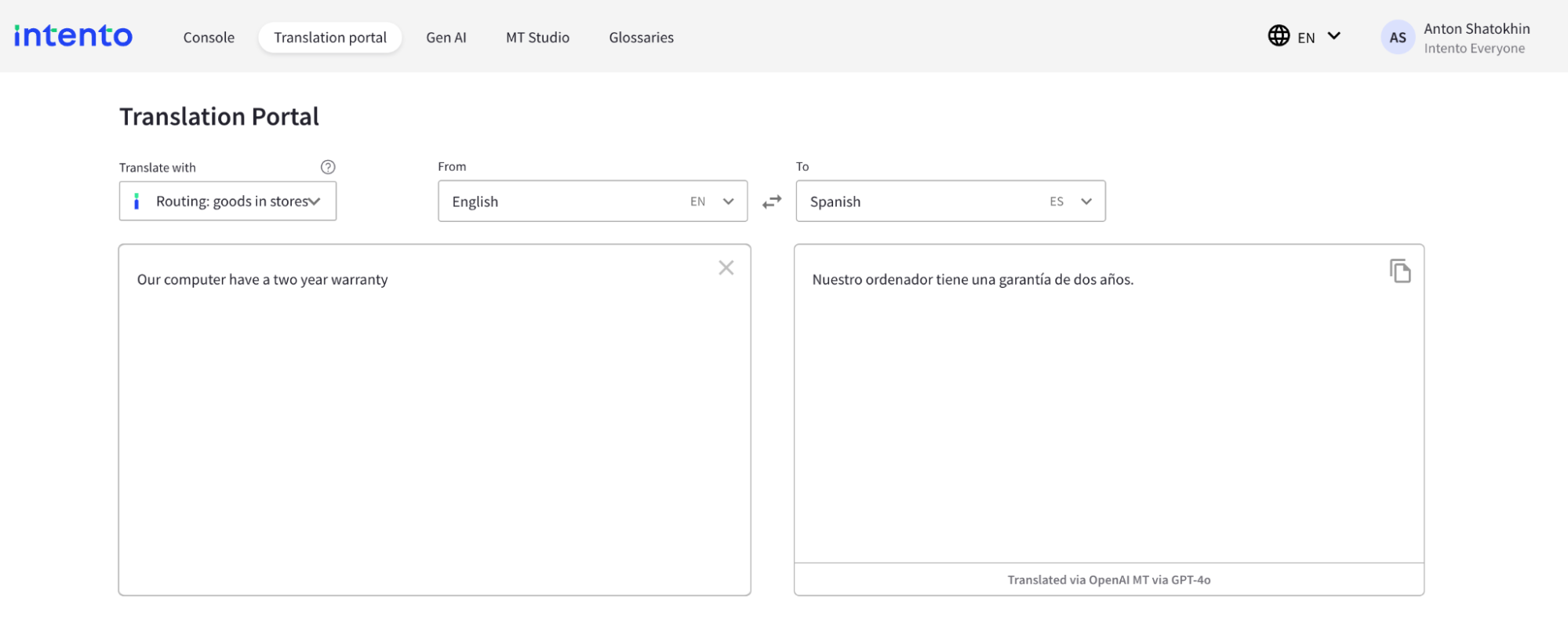
With glossary