
1.7.1 Why humans?
The second part of the MT evaluation is the human part. Humans must be involved in evaluating MT quality for many reasons. You cannot replace humans with any automated metric.
Well, sometimes you can if you do something like an automated reader, which you do, for example, in pharmaceuticals, because so many papers are published in medicine that you just cannot read them manually. Once you built an ontology in one language, we built ontology in another language. Then you can evaluate translation pretty much automatically.
Based on those ontologies, because it will be a robot reading using that, you involve robots to relate content for robots and involve humans toward content for humans. Simple.
Once we have AI rights in Constitution, there will be a requirement: you should not let humans decide for AI what content to you, as well we should not use AI to decide for humans what content to use.
When you pursue improvement of post-editing, you do a human evaluation. Either editing efforts (it may be time, words per hour), if you have an in-house team, or you may estimate the rates if you have an outsourced team where you pay per word.
For that, you need to do LQA or trial post-editing of many outputs of MT and see what you have there.
For end users, you need them to evaluate understandability, inclusivity, bias, and risk. So do a holistic review. It would be best if you did not care about MTQE, MQM, and DQF. Care about what end users think and if it helps with their job.
One big reason to involve humans in the evaluation of post-editing: with one customer, we ran a fascinating study. We were able to measure time. There were lots of post-editors editing the same content. Moreover, we found in that project that the choice of machine translation affects post-editing time. Fourfold.
Time may differ four times, depending on the machine translation engine you used. However, the proficiency of the person makes a tenfold difference. You cannot evaluate the post-editing time without actually this person or company doing this post-editing because it depends more on that than on MT.
It would be best if you involved them.
You need to validate the results with your post-editors. If your post-editors before that were translating documents in Word, just blind typing without even looking at the MT suggestion, whatever MT you give, it would take time for them to learn how, and they may not be willing to do that.
If you come to your LSP and say,” Oh, that is the best model, Intento says it is the best MT model. How fast can you edit this MT?” They cannot tell you if they did not try, and the best you get is an honest answer that they do not know.
If you are a big company, you may tell them: “Oh, that is my best MT; I want a 50% discount now.”
And they have to agree because you are their biggest customer. If you churn, they have to fire half the people, and they agree, and then you guess what happens, right? Your quality goes down, translators starve, and that is not the right thing to do.
Another important thing is that end users know more about their needs than linguists, that is for sure. We had many cases where support agents revolted, saying, “Who selected this MT system? Show me this person! Please give us outputs from models. We will select ourselves.” Then they selected a different system.
There are lots of subtle differences you may see. You may notice that even for German, if you do evaluations with end users. People from the US, Germany, and Switzerland will select different systems, different stock models for German.
End users need to feel involved to be convinced because you can build the integration with engineers, but if your end users do not want to use it, they will not. They need to feel involved and be in control because it affects their daily life. That is the reason why you must have humans in evaluation.
Your goal is not to add this activity to them as another unpaid job and duty. That will not work. You need to reduce the amount of content to review so that it is not very mind-boggling, and still, they can make an easy choice.
We went through that. Depending on the use case, you can assess effort, understandability, translation risk, source quality, and other aspects.
For example, tone of voice feedback from end users is invaluable. We would never know that there are two informal in French and formal-informal Turkish if they did not tell us.
1.7.2 Sampling the content for review
So how do we do that? Three reviewers, 30,000 words each, 90,000 words. Infeasible. Random sampling is prone to outliers; it does not work. Out of these 90,000 words, we want to find some content for them to look at. Like an executive summary, if you will. How do we do that?
You may look at all your content from the perspective of content difficulty and the agreement of different engines on how difficult this content is. It is tricky when it comes to how you calculate that, but let us leave it outside of discussion by now.
Once done, you may see sentences that are hard for every MT. Translating them is hard for every model and will be hard for your human translators.
It means you must look at why MT engines fail with them, most likely because you have to do something with the source content. You either do not use MT or need to do something with the source content. It is enough to get very few of those segments to understand what is happening; 50 segments will be enough.
Now it is time to assess risks. We use a special algorithm to find sentences that are hard for one MT engine but not for the others. Let us call it quirks. Every engine has quirks. There are some particular combinations of words that make it trigger and produce garbage. We look at those segments. And then, for effort estimation, we do not want any outliers because, in production, we have significant numbers, and we want to see an estimation that will reproduce itself on big numbers.
For that, we sample from the middle of a distribution with 1000 words for trial post-editing. Depending on the use case, there may be more errors to focus on, but these three are the most typical.
That is the general approach of applying AI to a situation where you cannot remove a human because you need human judgment. It would help if you focused their attention.
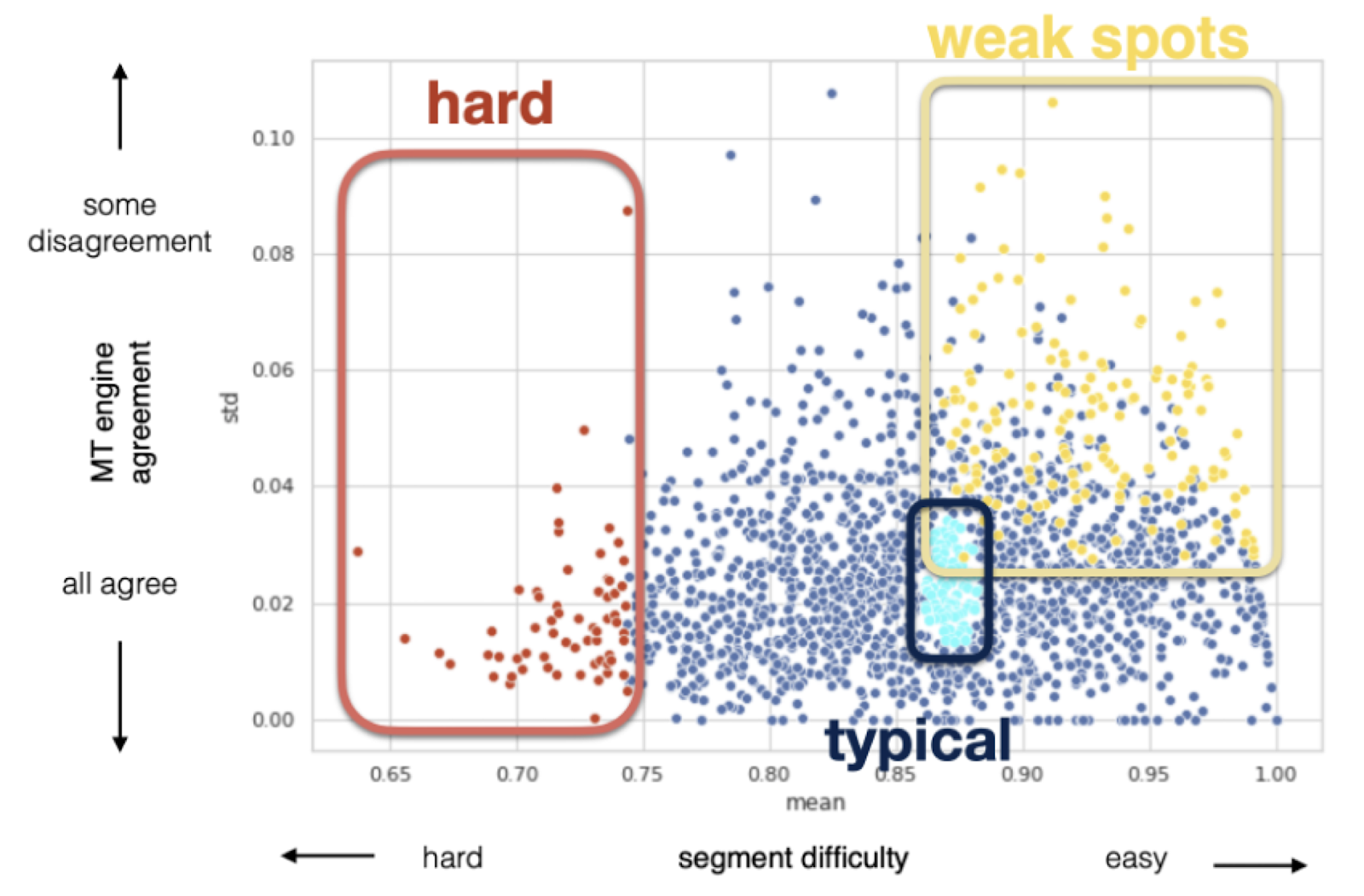
Picture 1.7.2.1
1.7.3 Weak spots / Translation risks
Identifying those weak spot candidates using our algorithm depends a bit on thresholds, but we found all issues. We have all of them; the question is how we classify them.
You may see typical issues: mistranslations, tone of voice issues, omissions, additions, translated DNT, not translated DNT, untranslated content, and so on. Typically, we look at very few, so we can just put linguist on. Sometimes you need a native speaker to understand what the issue is. We are not an LSP, and we had six linguists when we prepared this material. They speak maybe 12 languages between them. Maybe more, maybe 15. However, for those cases, we sometimes rely on back translation and multilingual models or automatically identify the issue type. It gives us a risk picture you may see in picture 1.7.3.1.
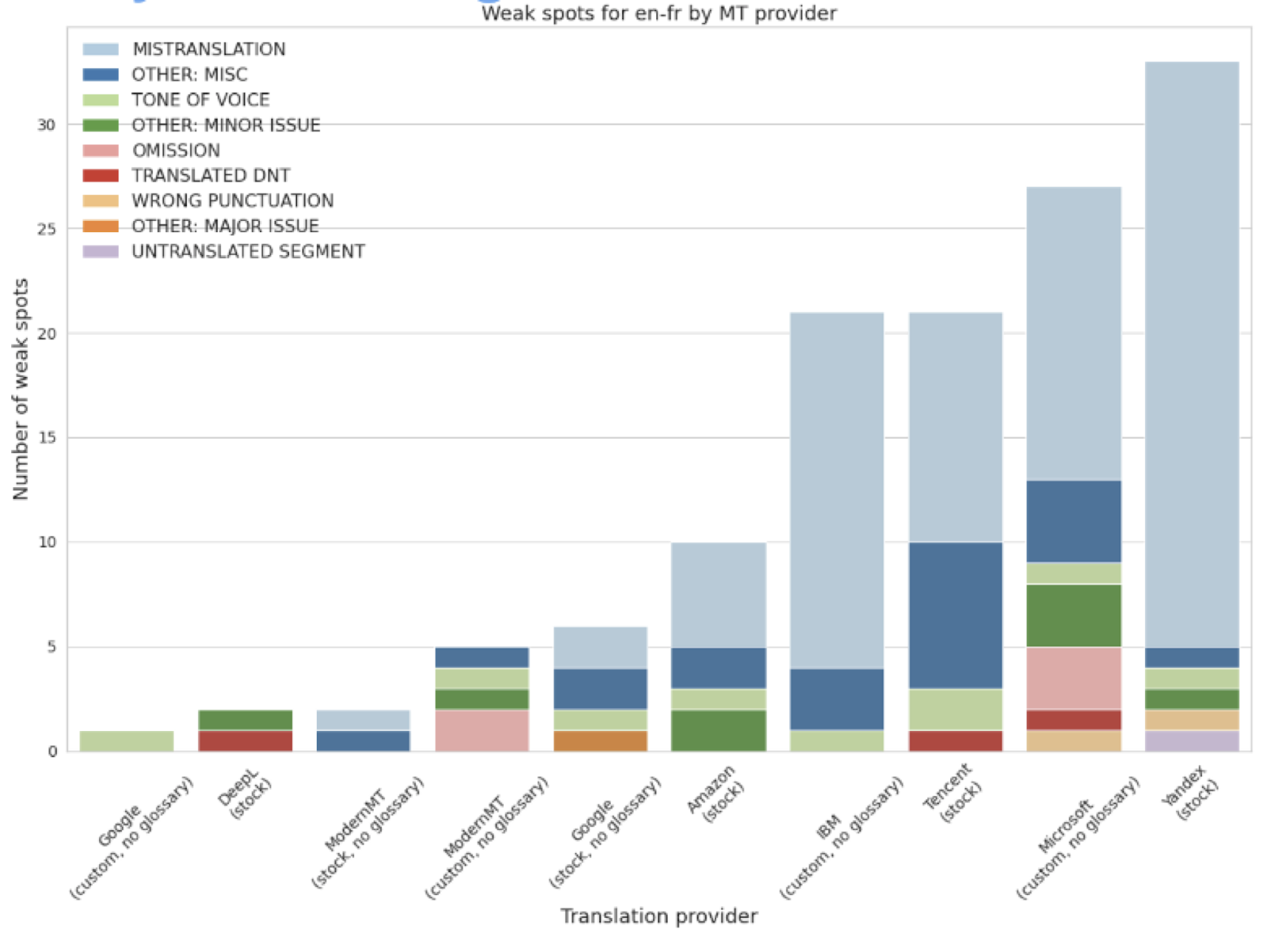
Picture 1.7.3.1
We have engines with lots of issues and low-risk engines. It does not necessarily mean that engines with fewer catastrophic errors produce high-quality translations on average. It may be very different. There are some I would call hit-or-miss engines. They either produce a very good translation, almost human quality, but if something goes weird with the source text, they fly in opposite directions; they break.
1.7.4 LQA process
With the LQA process, we do not calculate any proxy metrics with MQM or whatever. We measure what we want to measure, editing effort. If we can measure the time, it is perfect; if we cannot, we ask reviewers to do post-editing and ask them to write their perceived effort.
Because sometimes, they know that it takes much effort to edit that in their TMS system, and for the perceived effort, we ask them to map it in somehow to how they feel it compared to TM leverage matches.
We typically talk to LSPs of our customers to get their effort estimates, either effort-saving estimates or productivity increase estimates for each of these types.
It is pretty straightforward. It is more than 100% effort if it is re-translation because you have to review it and retranslate it. And then you save, for example, if it is perfect, it is only review, it is typically 10% effort, 90% effort saving.

Picture 1.7.4.1
We involve three reviewers per segment. Because we notice that reviewers have different personalities. Those are the three most popular from our MT evaluation for Playrix (see picture 1.7.4.2)

Picture 1.7.4.2
The first one is with high polarity: that is perfect, or it is useless. We saw this type of reviewer.
We have optimists, realists, and pessimists, especially when it comes to their rates, and they expect that it will negatively affect their rates. They would say, “it is just all useless.”
We have a way to assess the agreement. You say see it on picture 1.7.4.3.

Picture 1.7.4.3
Of course, all the time, we mix in a placebo. It is a human translation, typically produced and approved by the same company that does this review, and we are not telling where it is.
It is essential because we tend to be overly optimistic about human translation quality. It is typically less than we expect, especially on the consistency side.
Sometimes we see machine translation coming first. Because the person decides, “Probably that is a human translation. Let me write it higher.” It helps to understand the relative between humans and machines.
Then we multiply those effort-saving coefficients. We get effort saving as numbers with statistical significance, and we can select the engine’s expected effort saving. Again, the pricing per time is perfect if we can measure time and if the time matters for this specific relationship between an enterprise and an LSP. It is effortless; it removes lots of headaches.
Then for end users, we do a holistic review. We will not go deeper into that in this article.

Picture 1.7.4.4
1.7.5 Putting it all together
We get different signals from all these types of reviews. What the risk is. What the end-user satisfaction is. What the post-editing effort is.
Then, we rank all engines, all models we evaluate. Sometimes we evaluate two use cases at once, and for one use case, we select one model, which for example, brings less effort to edit. We might select another model with more stable output for another use case.

Picture 1.7.5.1
We often found that post-editors do not care about critical errors. Such errors are easy to spot. Post editors immediately see them and translate them from scratch. They do it. If they are fairly compensated for that, that is it. They do not care.
Typically we select two winners per this category because, as we mentioned, every MT provider has bad days, and you have to go for a backup model. You have to have this backup model.
Hard segments, weak spots, and reviewer comments help us to set up these pre-processing, source quality improvement, and automated post-editing steps on our side because we address what people have troubles with. As was presented on the project we ran with e2f a couple of years ago when we saw that for post editors, the biggest problem was a tone of voice. So once this automated tone-of-voice control was added, post-editing speed increased by another 50%.
Depending on the use case, you may want to evaluate other things, such as tag handling, glossary handling, tone-of-voice, gender, geo names, and many more.