
Introduction
Machine translation technology has come a long way in recent years, and the landscape of available options can be rather complex. Many machine translation providers offer pre-trained, customizable models for specific domains and frameworks that allow users to train their models from scratch. In this article, we will explore options available for customizing machine translation engines and the build and production phases of MT management, including training and reference data preparation, the customization, evaluation, integration, and adoption of MT, feedback collection, model and glossary updates, technical issues, quality, and re-evaluation. We will also discuss the importance of staying up-to-date on trends and changes in the space and making necessary updates as these occur.
Types of MT models
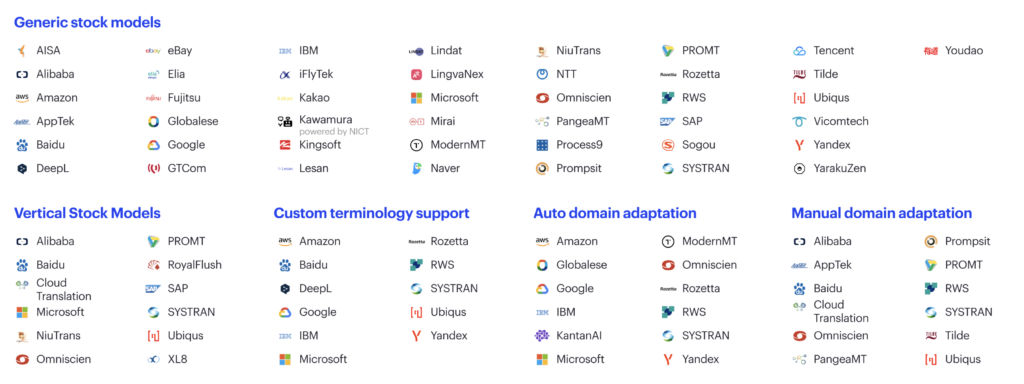
The machine translation landscape is quite complex today. There are many MT providers with generic, pre-trained models.
Generic does not mean the engines work on general content like news and media. Instead, it means they are trained across many domains.
In general, every good machine translation provider knows how to deal with out-of-domain data, and they have lots of small models under the hood. These models may be rather good in many domains. However, they may easily misinterpret the domain when there is a lack of context, resulting in bad translations.
Many MT providers have vertical models – stock models, so they do not need to be trained. These models are biased towards certain domains. SYSTRAN, for example, is notable there because they provide a marketplace of such models trained by different companies.
There is something worth noting about vertical domains and domain-specific data in general. Very often, the same domain in two organizations will be technically quite different. For example, you may have an IT domain in two different organizations. However, given their differing terminology bases, tone-of-voice, style guides, and other factors, there will be significant differences between them. Keep this in mind when comparing vertical domains and domain-specific data.
A number of machine translation providers offer separate custom terminology support. You can add a glossary even if you do not have data to train a model.
A number of machine translation providers support automatic domain adaptation. In other words, you can take your translation memory (TM), upload it, press a few buttons, and get a trained custom model. The result depends on how much data you have, the quality of your data, and what training algorithms the MT provider uses.
Training a custom MT model
There are at least three different ways to train a custom MT model. The most typical case is an auto-domain adaptation in which a user uploads the data and gets a dedicated deployed custom model. Some MT providers have dynamic adaptation, where adaptation can happen in real-time with new segments continuously added to the data. ModernMT and Amazon are examples.
Then there is always manual domain adaptation. If you pay enough, you can always make a domain adaptation of virtually any model of any MT provider you want. You just pay the provider, and they take care of it. Typically, this is left as a last resort because you would first want to consider faster and cheaper options.
Other MT frameworks
In addition to the options discussed so far, there are other frameworks to consider.
There are NMT frameworks you can download and train from scratch. Get public data and add your own. There are openNMT supported by SYSTRAN, MarianNMT by Microsoft, Sockeye by Amazon, FAIRSEQ by Meta AI, and a framework from NiuTrans, a Chinese MT provider.
Also, there are SMT frameworks such as Moses, and they are still valid, for example, for back translation. If you lack data, SMT works well.
Next in the landscape are rule-based frameworks, such as Apertium, and a commercial version, Prompsit. They are still helpful when you want high-quality, customized models for low-resource languages or dialects. You build a model for the main language of the group, and then you cover the last mile with a rule-based model.
Recently, multilingual pre-trained neural models suited for machine translation, such as OPUS, mBART, M2M-100, and NLLB-200 (No Language Left Behind), have become available. These models are particularly useful when working with low-resource languages. However, they tend to produce lower-quality translations for high-resource languages when compared with commercial MT providers.
An analogy that illustrates the challenge here can be as follows. Imagine you have cookies of different sizes on a single plate and want to bake them. If you bake all the cookies at the same time, some of them may become burnt while others may remain underbaked. In order to achieve the desired results, you must be clever and strategic in your approach.
With open source, you must meticulously check licenses. It is important to ensure that the data has a license that allows for commercial use. Using data with non-commercial licenses can result in your model inheriting this non-commercial license too. It is crucial to be mindful of this issue to avoid any potential problems.
MT Management in a Nutshell
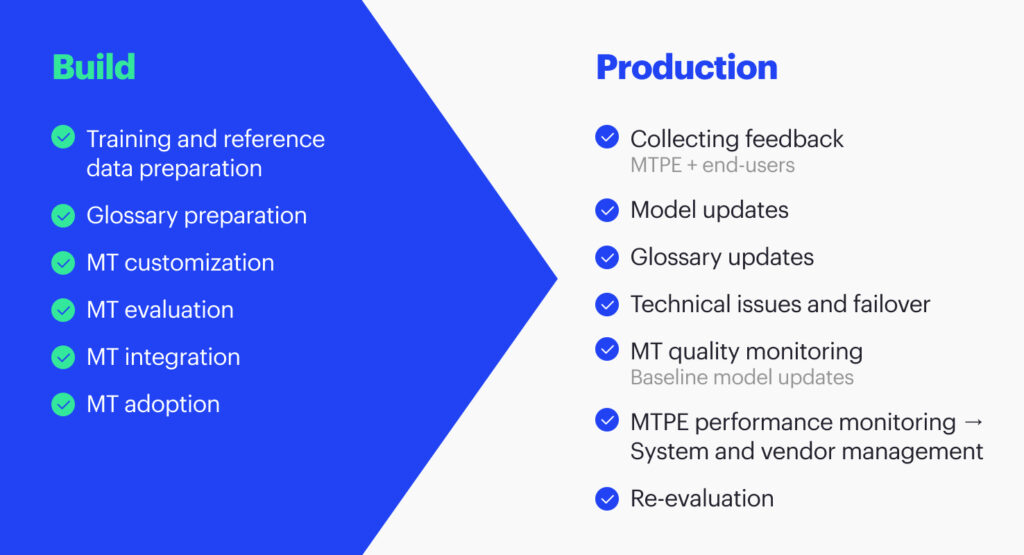
The overall process you will go through is similar to the image above (Figure 4). It will typically involve a build phase for preparing training and reference data, creating a glossary, customizing MT, and evaluating (and, ideally, customizing) all the platforms you can. You may call it procurement or evaluation.
After evaluating the various options, you will select the best machine translation option and integrate it into your systems. Convincing people within your organization to use MT as part of your workflow is also beneficial.
What to consider when implementing MT in an enterprise
There are two stages to consider when implementing machine translation in an enterprise setting: the launch/production phase and the ongoing usage phase. During the launch/production phase, it is important to collect feedback from post-editors and end users, update the models and glossaries as needed, and address any technical issues that may arise. You need to deal with technical issues and have some failovers because any technology now has some downtime.
As changes happen
It is essential to track how technology works, as machine translation providers may update their models without notification. You should regularly check to ensure the technology is functioning as expected. Additionally, it is important to monitor post-editing performance to negotiate better rates. As MT improves, so does the quality. Therefore, you want to ensure the work and rates are appropriate for the changing situation.
Furthermore, periodically reevaluate your use of technology as shifts in the industry occur. These include releases of new models by companies like Amazon, Microsoft (which released Z-Code to customized models), and Google (which released significant improvements in the quality of low-resource languages).
The annual State of Machine Translation report is a resource for those who may not have the time or budget to evaluate machine translation technology thoroughly but still want to get a general sense of how well stock models perform. Just get a baseline to see how stock models work well. In 2022, we evaluated about a million translated words in nine domains to 11 languages.
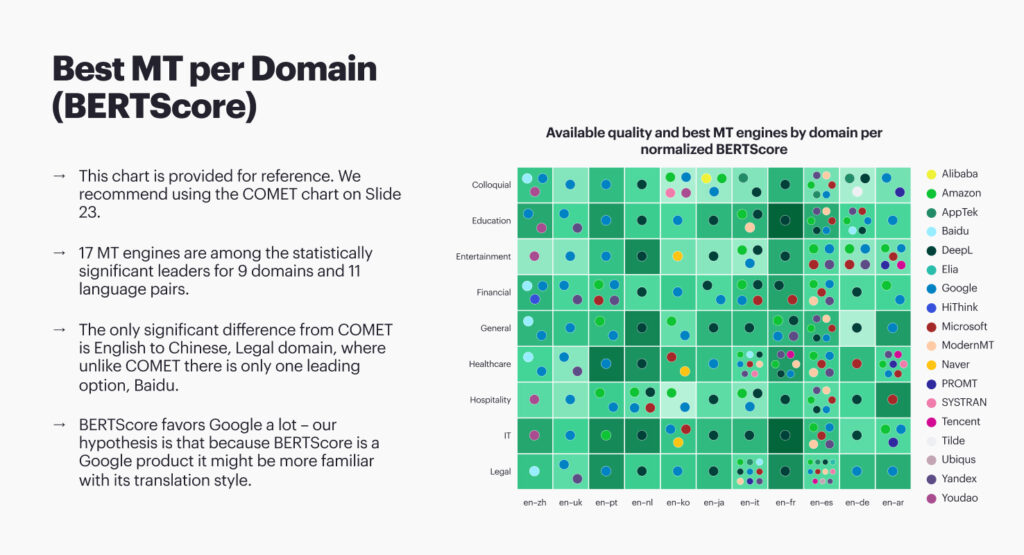
In The State of Machine Translation 2022, we ran 31 models across those words and measured the results using different MT scoring metrics. The main one was COMET. There will likely be different rankings on your specific content. For example, we have tried the financial domain, but your financial domain can be different: different terminology and currencies. Still, results are helpful for companies in many cases. Additionally, we embedded this in our automatic routing, so when somebody translates something with no engine preference, we send the translation request to a machine translation provider based on our evaluation.
Considering total costs
Before evaluating the engines, aside from quality, you need to consider the total cost of ownership. This consideration comprises not only what you pay to translate one megabyte of content. Instead, it is all the fees of MT providers. You should consider that custom MT models typically cost four times more than stock and work more slowly and less reliably. If the quality of custom and stock models is about the same, go with the stock. In this case, the only downside of the stock model is that vendors will update it from time to time. There is no snapshot you can rely on, so you have to check that it still works as expected.
There are associated fees to consider when it comes to customizing machine translation. Deep customization, such as with Google Translate, incurs additional costs. However, more lightweight dynamic customization options, like Modern MT or Amazon, do not typically require payment as they do not involve the use of GPUs.
Using glossaries also plays a role in the total cost of ownership. There are dynamic and static adaptation options. You can incorporate glossaries into the model during training, similar to what is done with Microsoft glossaries. Updating the glossary requires retraining the mode, which can impact the overall cost of ownership. Errors and dynamic glossaries are added on top, which is less expensive.
When considering an on-premise private cloud solution, it is essential to factor in hardware costs and compare prices. Keep in mind that the cost for an on-premise solution typically excludes hardware costs, making it difficult to make an apples-to-apples comparison. Additionally, it is important to consider the necessary hardware and GPU scaling to match your volume.
Integration costs
Consider integration costs. You have many-to-many integrations if you want to integrate a few models with a few internal systems. If you choose traditional integration methods, you will need to build multiple integrations either through a platform like MuleSoft or with the help of engineers. A better option would be to use an integration platform that supports this, like Intento Enterprise Machine Translation Hub. This type of work will require building and supporting multiple integrations because MT APIs and software versions will change.
It is not enough to build an integration; oftentimes, it also needs to be updated with new versions of the software system. In 2021, Intento built integrations with several software that only a year later needed updates. In many cases, these announcements are released with very little warning.
When configuring and managing machine translation, it is essential to remember that someone will need to pull the levers. AI alone will not suffice, and it should be either an in-house team member or an outsourced professional. It is important to budget accordingly, as the cost may be high depending on the complexity of the task.
And then, finally, you have many decisions to make: do I build or buy this third-party software? Do I use in-house software, outsource services, or hire people? There are pros and cons for all these decisions related to expertise and onboarding.
Takeaways
- The machine translation landscape is complex, with many MT providers offering pre-trained models that can be customized for specific domains.
- The final translation quality will depend on the amount and quality of data used to train the model. Without context, generic pre-trained models may easily misinterpret the domain, resulting in poor translation.
- There are multiple ways to train a custom MT model, including auto-domain adaptation, dynamic adaptation, manual domain adaptation, and MT frameworks that can be trained from scratch.
- When evaluating machine translation engines, it is essential to consider the total cost of ownership, which includes all of the fees associated with the MT provider and not only the cost of translating one megabyte of content.
- Traditional integration of a few models with internal systems requires building multiple integrations using additional resources and ongoing maintenance, as technology updates happen often and without sufficient preparation time or notification.