
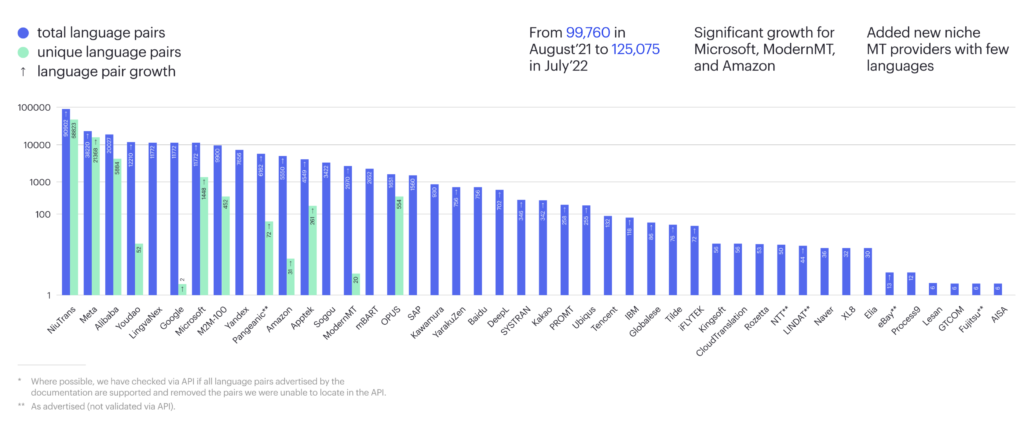
To choose an MT system, start with language support. In 2022, there were 125,075 supported language pairs. From August 2021, Microsoft, Modern MT, and Amazon have grown their number significantly. The leading contributors are Chinese companies NiuTrans and Alibaba as well as US-based Meta.
Just because a provider supports a language does not guarantee high-quality translations, especially for less common languages like Basque or Icelandic.
Pricing
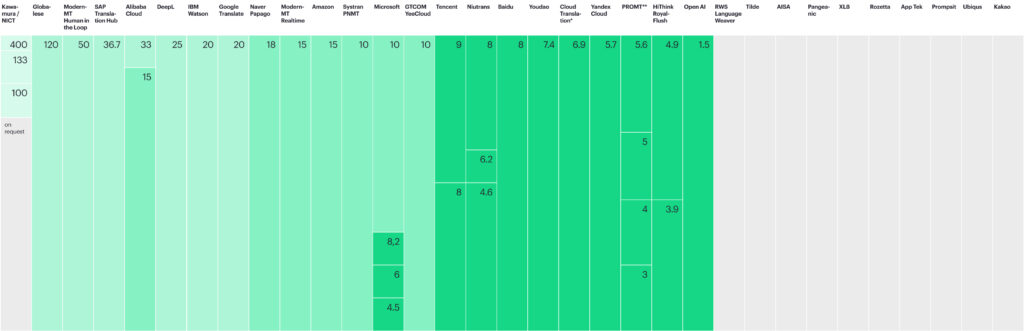
When selecting an MT provider, consider pricing ranging from $1.5 to $400 per million characters.
This does not necessarily reflect quality. Sometimes cheaper options may suffice, and sometimes more expensive options might be preferable. Using custom MT models typically costs four times more than using stock MT. The prices in Figure 28 are public, and volume discounts may be available, so always discuss pricing with the provider.
Available glossary/Custom technology
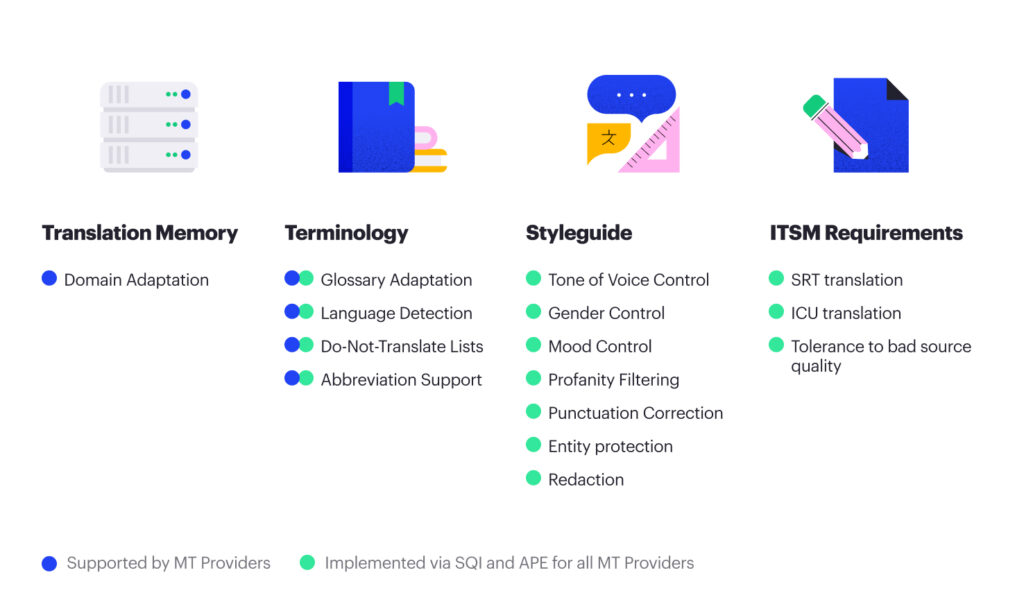
Data assets play a major role in choosing an MT engine, with glossary availability being a crucial factor. Training cannot replace glossaries; You need a dataset with consistent terminology where terms appear multiple times for machines to memorize them. Only some have such datasets. If you need to replace a term, you must retrain the model with examples. Retraining MT is a time-consuming and potentially costly process unsuitable for changing individual pieces of terminology. Some MT providers allow for training in a dictionary, but this does not eliminate the need for time-consuming retraining when replacing or adding terms.
Custom terminology support is offered by Amazon, Baidu, DeepL, Google, IBM, Microsoft (trained-in or dynamic), Rozetta, RWS, SYSTRAN, Ubiqus, and Yandex (dynamic glossaries only). Most providers replace terminology as is, word for word. Some providers, such as SYSTRAN, DeepL, Phrase, and Yandex, support morphology for specific language pairs. These aspects may be important to you depending on the terminology you use and the language pair. For example, you will have no problem with terms that do not need a translation. However, if you translate bilingual terms into inflected languages like Arabic or Polish, morphology can be crucial.
At Intento, we have combined providers’ terminology support capabilities into a unified interface and added terminology support for providers that do not yet offer it. Our glossary technology works in a provider-agnostic way, enhancing native features across all providers.
Available translation memories
The amount of data you have can influence your choice of MT system:
- IBM, Google, Globalese, Microsoft, Systran, Yandex, Rozetta: Deep training, static only; technically starts with 5-10K segments, but ideally, you should have 100K for cleaning.
- Amazon, ModernMT, Kantan: Lightweight training, static and dynamic; begins with one segment, but having more is recommended.
Begin with a stock or domain-specific stock model. As you gather data, switch to a dynamic model, and then, as your data volume increases, consider using a static model.
Providers supporting auto domain adaptation include Amazon, Globalese, Google, IBM, KantanAI, Microsoft, ModernMT, Omniscien, Rozetta, RWS, SYSTRAN, and Yandex.
Domain adaptation – useful hacks
Training custom models without using English is often challenging, but Amazon, Globalese, ModernMT, and SYSTRAN are exceptions. For instance, they can create custom-trained German to Italian models.
If you need a custom model for a dialect or a low-resource language, try training a custom model for the primary language in the group (e.g., English to Spanish) and use rule-based machine translation (Prompsit, Altlang, or Apertium) to transition to a neighboring language (e.g. Galician).
Another tip: Microsoft offers domain-specific baseline models, so you can use general data to “train” the custom MT in your domain.
Other requirements
When preselecting MT models, consider these additional factors:
- Security and privacy regulations: Consider the company’s location, ownership, model location, and data storage for training.
- Compliance with OFAC regulations and other requirements.
- Data locality requirements: Ensure you can send data as needed or have contractual clauses in place.
- Data retention, protection, and confidentiality (watch for opt-outs!).
- Wake-up time: Some models may turn off after inactivity, and wake-up times vary by provider. Consider backup models.
- Response time: Custom models typically have longer response times than stock models.
- Stability: Custom models might have more errors or issues, so be prepared to handle potential problems.
Available features
Organizations may have varying use cases that require specific non-linguistic features. Support for these features across different MT providers can be limited or unclear. Documentation might state that a feature is available, but its quality could vary between language pairs in practice. Depending on the language pair, the model may handle inline tags differently, such as doubling or duplicating them in specific languages.
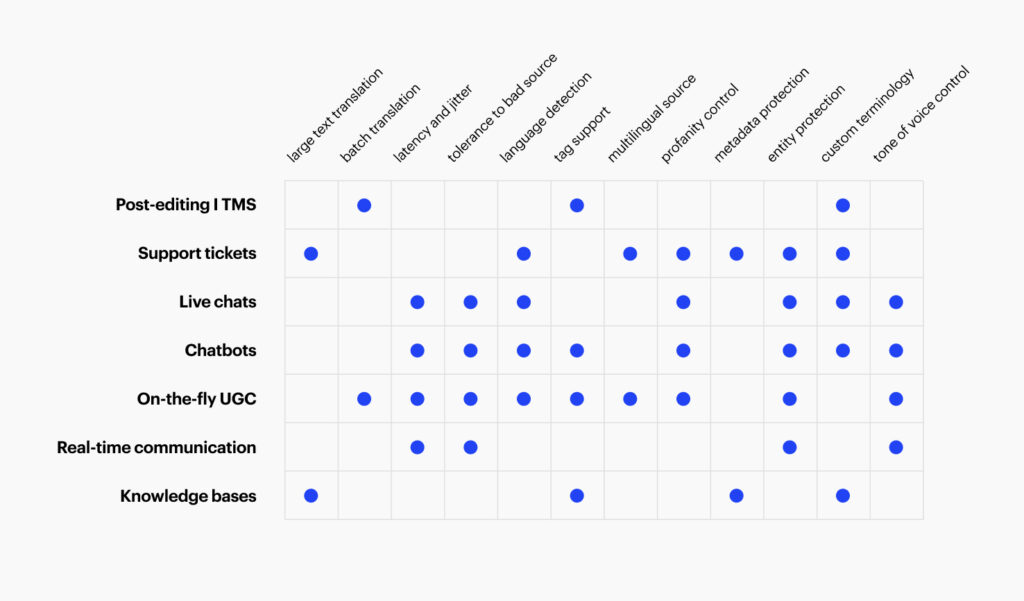

Intento has developed universal support for these features, working seamlessly with almost all providers. We preprocess data before machine translation, perform automated post-editing, or both. Most features can be implemented on top of any MT system, allowing you to maintain translation quality without sacrificing features.
Takeaways
- Evaluate language support: Choose an MT provider with solid language support, but be cautious of translation quality for less common languages, or choose a system that supports several MT providers.
- Consider pricing and custom models: Assess MT provider pricing and weigh the benefits of custom models, which are typically more expensive but offer better performance.
- Prioritize glossary availability: consider providers that offer custom terminology support or use a system that allows using glossaries on the top of MT.
- Assess non-linguistic features: Identify any specific non-linguistic features required and evaluate the MT provider’s ability to support these features while maintaining translation quality.