
The use of translation memories (TMs) is crucial when training machine translation (MT) models. However, it is essential to understand and address the typical data issues, such as duplicates, inconsistent translations, or technical issues, to prepare the data assets effectively. This chapter explores the data issues that should be addressed when working with TMs and the tools available to automate data cleaning. By addressing these issues, you can improve the quality of the data used to train MT models and ensure their performance. We also explain the importance of glossaries, including their different types.
Working with TMs
Typical issues with data
Some typical data issues should be addressed when working with translation memories (TMs) to train machine translation (MT) models. While a fully trusted human translation memory might seem like a good choice, there may be better options for training MT engines using all the data as is. Even if most MT providers that offer automatic domain adaptation clean the data before training, it is essential to understand what parts of the cleaning process they perform. To ensure transparency and control, our approach involves cleaning the data ourselves so that we know what we are removing and changing.
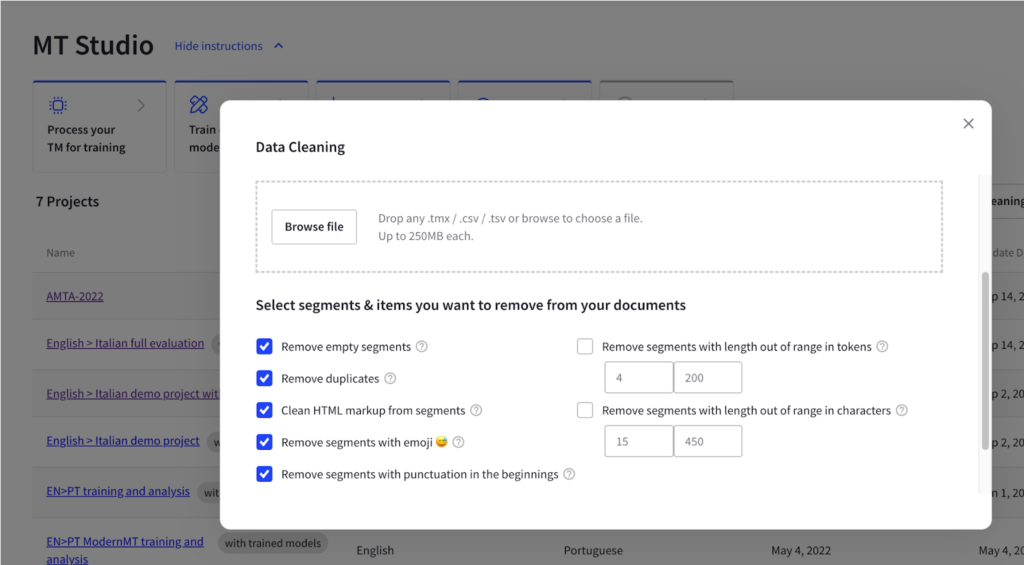
It is essential to be aware of the typical issues data may have, such as duplicates, which can account for up to 60-80% of the total data. If you have 40,000 segments in your TM, you likely have only 15,000 segments of training data before any other cleanings. Other issues to watch out for include segments that are too long or too short, mistranslated or mismatched segments, text in the wrong language, technical issues (like emojis, junk, broken Unicode, HTML entities, placeholders, tags, and patterns), empty segments, sentence fragments, and transcreated segments (which are especially important for marketing content).
Additionally, inconsistent translations can occur when multiple translators work on a project in parallel, translating the same phrase or term differently. Ensuring that translations match the glossary and the correct data regarding currency formats and company names is also essential. By addressing these issues, you can prepare your data assets to train your MT engines more effectively and improve their performance.
Tools to automate data cleaning
To help with cleaning TMs, there are a variety of tools available. One option is OpenRefine, which is a great tool for non-technical individuals. This tool, formerly Google Refine, can help clean data and make it more manageable.
Jupyter notebooks (Python notebooks) are also an option for more technical individuals. You can find open-source notebooks and adjust them to your specific needs. This is particularly convenient for sharing within your company.
Additionally, many TMS include cleaning tools, but knowing precisely what was cleaned out is essential. When you encounter incorrect results after customization, it is essential to understand the reasons behind the issue – whether it is due to the wrong MT provider choice, problems with data, or a combination of both.
Several popular tools for TM editing include Okapi Olifant and Goldpan. Okapi Olifant is a widely used and popular free and open-source cross-platform application for TM editing. Goldpan is a product developed by Logrus Global for TM editing. While it was initially developed as an internal tool, it is now available for use by the public. Goldpan is a desktop tool. Xbench is another desktop tool mainly used for QA, but people also use it for TM cleaning.
Finally, Intento MT Studio offers TM cleaning options to prepare the dataset for further custom MT model training.
MT providers also perform some automatic cleaning processes. If you are working directly with an MT provider, ask them to update you on changes they make in this field. This can give you insights into how they clean data and the pros of their approach are typically what they have on their site, tailored to the type of adaptation they use.
However, it is essential to note that these automatic cleaning processes may not detect mistranslations or glossary inconsistencies. Therefore, taking care of these issues yourself is necessary to ensure the highest data quality for your MT engine.
Dataset split
It is recommended to split the dataset into three parts: training, validation, and test. The training and validation sets are used during the training iterations, while the test set is used to check the model quality on the data the model did not see. Ideally, the test set should consist of 2000 segments. While any MT adaptation tool can perform the split, it is essential to note that different tools may split the data differently, resulting in overlaps between the training, validation, and test sets.
To ensure the accuracy of the MT model, metadata should be included in both the test and training sets. This allows an evaluation of the model’s performance across different content types. If there are discrepancies in the scores between different content types, training separate models for each content type is recommended.
Managing the split to control the old and new models is also essential. When updating old models with new data, it is crucial to ensure that the new data is not already present in the test sets.
Furthermore, it is crucial to be aware of concept drift, where some translations may become outdated, and terminology drift, where translations may still be accurate but the terminology has changed for some reason.
Glossaries
Types of MT glossaries
MT glossaries are an essential part of any machine translation workflow. There are different types of MT glossaries, including:
- Do-not-translate list: This glossary includes words or phrases that should not be translated. For example, “Medicare” in English should be kept as “Medicare” in Spanish.
- Proper nouns: These are names of people, places, or organizations that should be translated consistently. For example, “Valencia” in English should be translated as “València” in Valencian.
- Abbreviations: This glossary includes commonly used abbreviations that may need clarification to MT models. For example, “AI” in English should be translated as “IA” in Spanish.
- Common word glossaries: This type of glossary includes commonly used words that may have different translations, and you want to stick with one. For example, “accuracy” in English can be translated as “exactitud” in Spanish.
- Expansion glossaries: They are used when a term or an abbreviation exists in the source language, but there is no corresponding term or abbreviation in the target language. In this case, human translators would typically translate the term more literally using more common words. An Expansion Glossary provides a pre-approved translation for such terms to maintain consistency and accuracy. For example, in English, the term “Drug Enforcement Agency” can be abbreviated as “DEA,” but there may not be an equivalent abbreviation in the target language. In this case, an Expansion Glossary can provide a pre-approved translation for “DEA” to ensure consistency and accuracy in the translation.
Using MT glossaries helps to improve the quality and consistency of machine translations. Maintaining and updating glossaries regularly is crucial to ensure the accuracy of translations and avoid terminology drift.
Glossary support
When selecting and customizing MT engines, it is essential to understand the two types of glossary support available. The first type is native support when a provider includes a glossary within the translation feature. The second type is adding a glossary on top of the existing translation. Depending on the use case, it can be achieved through various tactics like search-and-replace, word alignment, or custom-trained large-language models. In Intento MT Hub, using glossaries on top is a critical component of the Automatic Post-Editing (APE) process, including other customization like tone-of-voice or conditional grammatical gender. That means Intento can automatically correct terms in translations received from MT providers even if providers do not natively support terminology.
Keep in mind that there are varying levels of case sensitivity among glossaries from different vendors. At Intento, we monitor these differences and have programmed them into our system. Here is a breakdown of case sensitivity by vendor as of date:
- Amazon glossaries are case-sensitive and require an exact match for source words within custom terminology.
- DeepL glossaries are case-insensitive.
- Google glossaries are case-sensitive by default, but a parameter can change this.
- IBM glossaries are case-sensitive.
- Microsoft phrase dictionaries are case-sensitive, while sentence dictionaries are case-insensitive.
- SYSTRAN glossaries are case-sensitive.
Morphology support is only offered by a few providers, including DeepL, Systran, Yandex, and Phrase. This support is necessary to use common words in MT glossaries without post-editing.
To build a comprehensive glossary, combining human and MT glossaries is crucial. However, if compiling a glossary manually, consider the case sensitivity issues. Another option is to automatically extract glossary, DNT, abbreviation, and short-string information from TMs.
Takeaways
- When working with TMs to train machine translation (MT) models, it is essential to be aware of typical issues with data, such as duplicates, inconsistent translations, and technical issues. Cleaning the data yourself can ensure transparency and control, and various tools are available to help automate the process.
- It is recommended to split the dataset into training, validation, and test sets to ensure the accuracy of the MT model. Metadata should be included in the test set.
- Glossaries are essential to MT workflow. Different types of MT glossaries, such as do-not-translate lists, proper nouns, abbreviations, and common word glossaries, can be used to ensure consistent translations. It is crucial to keep glossaries up-to-date and to understand the reasons behind issues with MT results.