
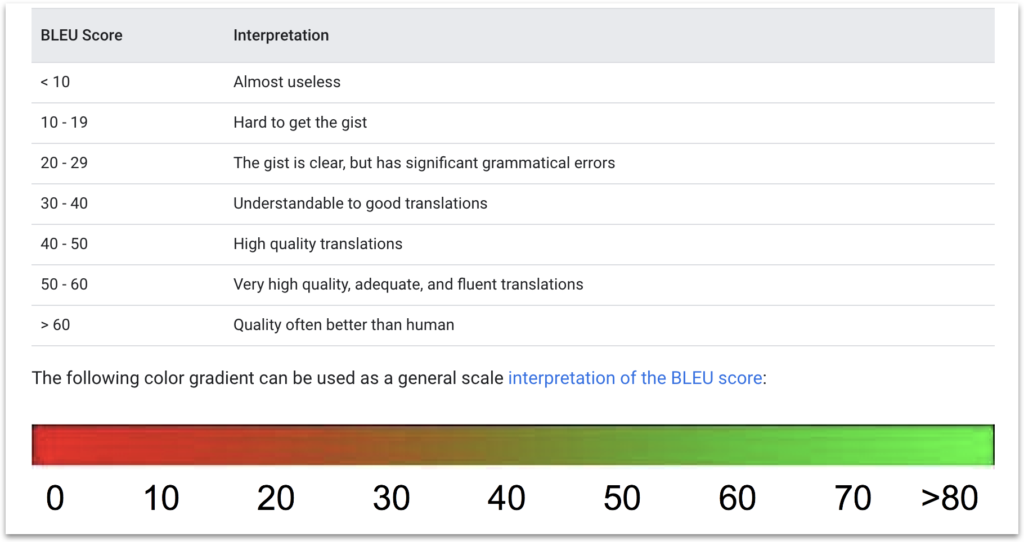
Understand what is under the hood
It is important to understand the training and evaluation processes in MT systems. Those systems are not foolproof, meaning they do not prevent users from making mistakes.
For instance, inexperienced users may simply drag and drop a TMX file into the training interface, press a button, and see their BLEU score decrease due to poor data. When actions do not yield desired outcomes, users may repeat the same process, potentially updating their existing model (if the provider has such an option) with the same data without retraining from scratch. This can cause training, validation, and test sets to overlap, resulting in a poorly performing model, while the BLEU score increase may seem impressive (exactly because of this overlap). A high BLEU score paired with gibberish translations in production can lead users to believe machine translation is ineffective.
To address this issue, MT providers must design tools to enforce proper processes. Although MT involves a certain level of artistry, adhering to a specific process is crucial. Unfortunately, many tools do not enforce this process, leading to subpar results. In this chapter, we will guide you through the training process on an example of training a custom model using Google Cloud, which is similar to other cloud MT providers with automatic domain adaptation.
Google Cloud example
When training an MT model in Google Cloud steps involved are
- Configure Google Cloud: Set up projects and permissions, and manage costs.
- Upload data and initiate training: Add your data to the platform and start the training process.
- Monitor successful training and quality score changes: Track the progress and observe improvements in the quality score.
- Analyze training and dive deeper: Evaluate the training process and explore further ways to improve your custom model.
- Update models based on data: Adjust and enhance your models according to the data and its performance.
Domain adaptation. Google Cloud. Configuration.
Getting started with Google Cloud can initially seem overwhelming, but the process is similar to other cloud systems. To set up your project, follow these steps:
- Create a Google Cloud project.
- Set up billing for the project.
- Enable AutoML and Cloud Storage API to use machine learning and upload training data.
- Create a Service Account and download the key (JSON).
- Configure permissions using Google Cloud CLI.
- Create a Google Cloud Storage bucket in the desired region using gsutil CLI.
Domain adaptation. Google Cloud. Training
Once you have created the storage bucket, the next step is to prepare your data. The requirements may vary between providers, so it is essential to follow the specific guidelines of the platform you are using. For Google Cloud, you can refer to their documentation for data preparation: https://cloud.google.com/translate/automl/docs/prepare.
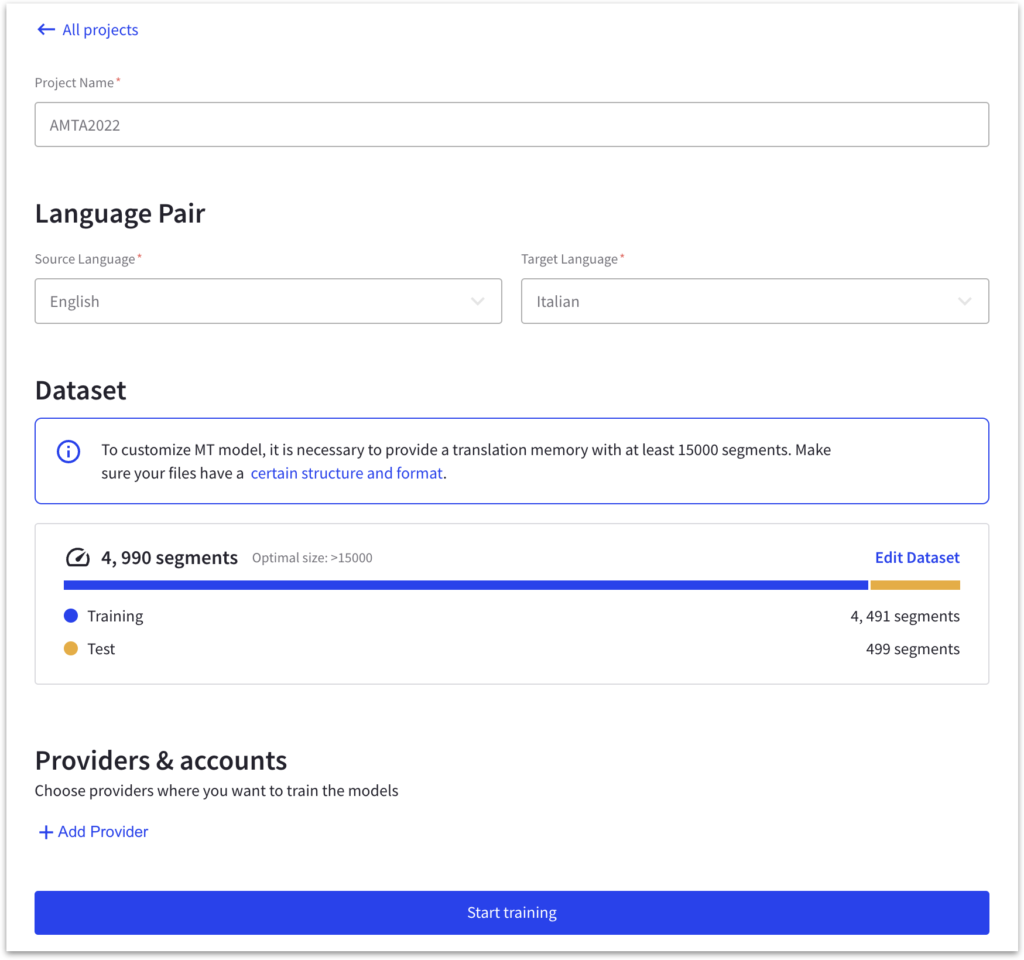
After preparing your data according to the guidelines, create a dataset in the user interface (UI) dataset and import your files into the dataset. This will enable you to utilize the data for training your custom machine translation model within the Google Cloud platform.
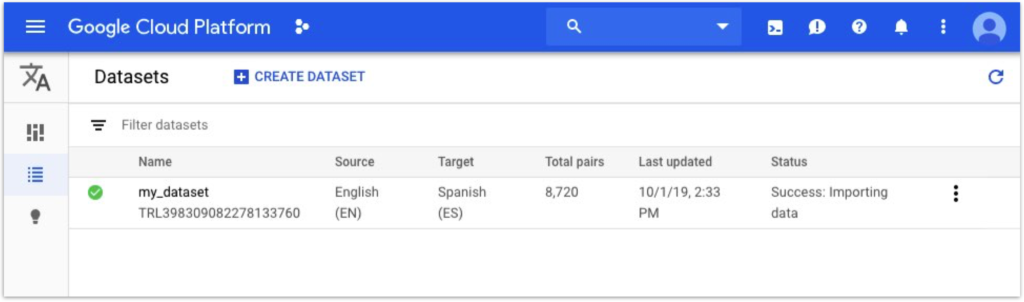
At this stage, you can import your translation files into the dataset you created in the user interface (UI). Ensure your translation files are appropriately formatted and prepared according to the platform guidelines.
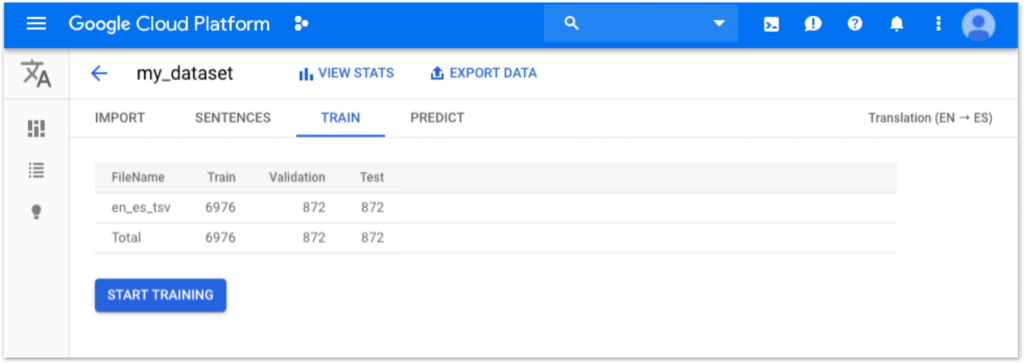
Once your translation files are imported, you will see statistics and an automatic split between train, validation, and test sets. While the default split is convenient, there may be instances where you would want more control over the division of your data, particularly for the validation set.
When dealing with different content types, ensure that all types are represented in the validation and test sets. This helps to evaluate the model’s performance accurately across all content types. Instead of training separate models for each content type, assessing how a single model performs for all content types is better.
In such cases, you can manually split your data during the preparation to maintain the desired distribution of content types in the training, validation, and test sets. This approach can provide better insights into your model’s performance and help you fine-tune it for optimal results.
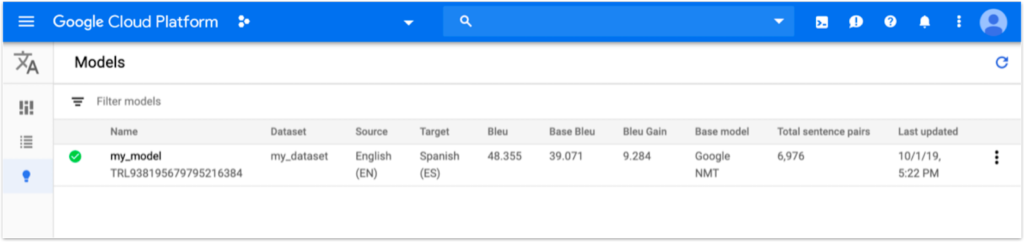
Once the model has completed its training, you will notice an improvement in the BLEU score, indicating the enhanced quality of your machine translation model. Additionally, you can review various statistics related to the training process, such as loss, accuracy, and other performance metrics. These insights will help you understand how well your model performs and identify potential areas for further optimization and improvement.
Remember that Google Translate allows you to run models in specific regions.
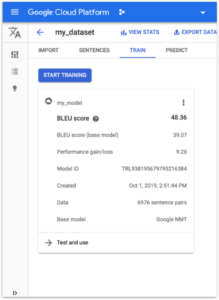
Domain adaptation. Google cloud. Using the model.
Keep in mind that Google Translate runs models in certain regions.
To integrate your custom model with your Translation Management System (TMS), follow these steps:
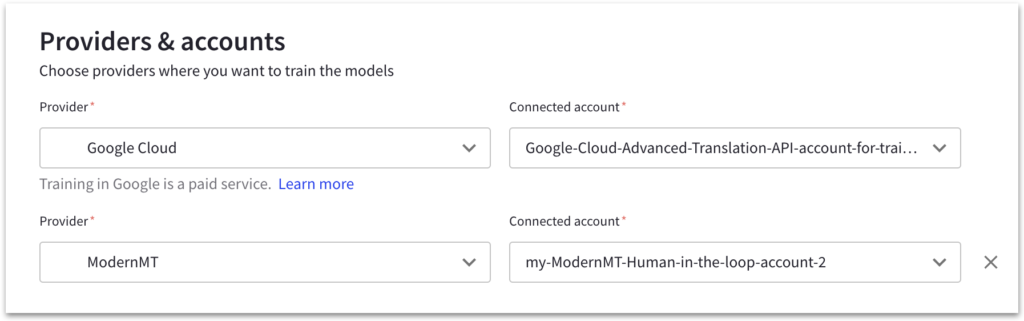
- Choose the appropriate TMS connector: If your TMS has a built-in Google AutoML connector, use it. Otherwise, you can use the Intento connector as an alternative.
- Authenticate using the service project JSON: In the TMS connector, authenticate by providing the service project JSON downloaded earlier.
- Use the model ID: Input your custom model’s ID into the TMS connector to ensure the correct translation model is used.
- Opt for Google Cloud Advanced API: We recommend using it instead of the AutoML API, as it supports batching, resulting in faster translation speeds.
Other platforms and considerations.
Different platforms have varying dataset requirements, such as data size, segment length, number of uploaded TMs, file formats, encoding, and escaping. Adhere to these requirements to ensure optimal translation results.
There are two primary types of model adaptation: deep (static) and lightweight (dynamic). Deep adaptation, like Google Cloud, is easier to build and validate as the model is trained once and then used over a long time. Lightweight adaptation, which is dynamic and adjusts on-the-fly, works well with continuously changing data but has limitations, such as, for example, constant data quality verification to prevent feeding a model bad data.
As your dataset increases, you might need to switch between custom machine translation platforms to ensure the best performance. When updating models, you often need to combine datasets and retrain the model, as most platforms no longer support training on top of existing models.
For large organizations, migrating models between environments can be crucial, especially in industries with strict regulations, such as pharmaceuticals. Some platforms, like Google Cloud, allow for easy model migration, enabling you to train models in one environment and use them in another. However, not all platforms offer this flexibility, and you may need to retrain your model in the new environment.
In summary, understanding the different dataset requirements, types of adaptation, model updating methods, and migration capabilities are crucial when working with custom machine translation platforms to ensure the best results and compatibility with your organization’s needs.
Was the training successful?
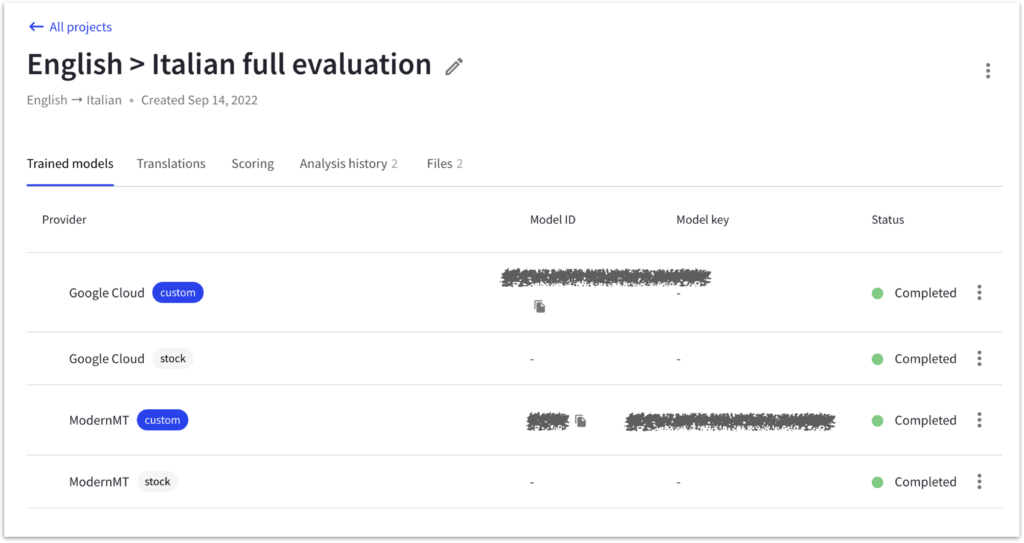
To streamline and simplify the process of training and evaluating custom machine translation models across multiple vendors, the AI Curation team at Intento uses an internal tool with a unified interface. This tool, Intento MT Studio, helps Intento analysts effectively handle the differences between various platforms. With this tool, our team can streamline the model training process, save time, and quickly compare the performance of models trained on different platforms, enabling us to choose the best-performing solution for specific translation needs.
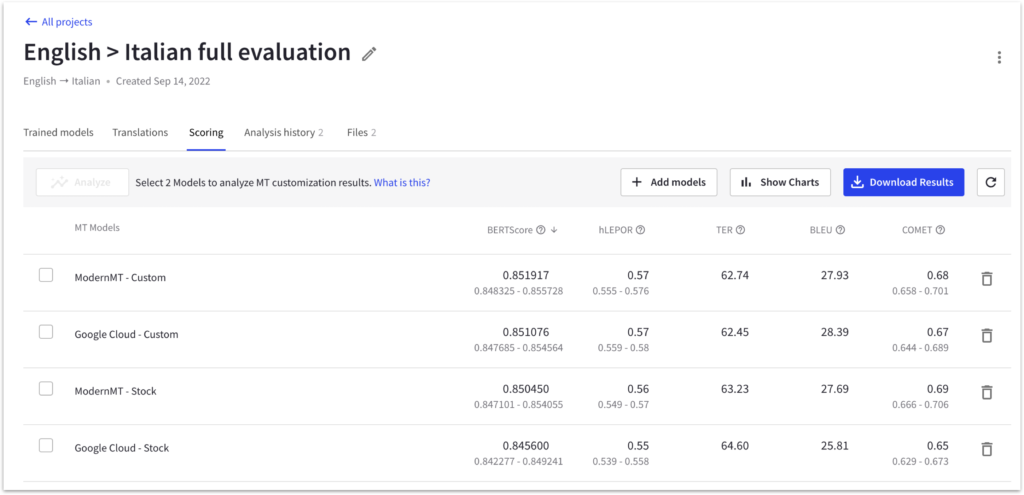
Intento MT Studio displays stock models alongside custom models, making it convenient for analysts to compare the performance of both models. This side-by-side comparison enables a more comprehensive understanding of the training process and its impact on translation quality beyond just the BLEU score.
By comparing stock and custom models, we can better evaluate the effectiveness of the custom model and identify areas for potential improvement or optimization.
While comparing scores for each model, confidence intervals to help us assess the stability of the translations. Wide confidence intervals may indicate that although the score improved, the translation quality became less consistent.
However, reviewing scores and confidence intervals alone may only partially understand the model’s performance. To gain deeper insights, examine the aspects behind these scores. This may involve analyzing the training process, data preparation, and other factors that could influence the model’s performance. By delving into the details, analysts can identify potential areas for improvement and ensure more reliable and accurate translations.
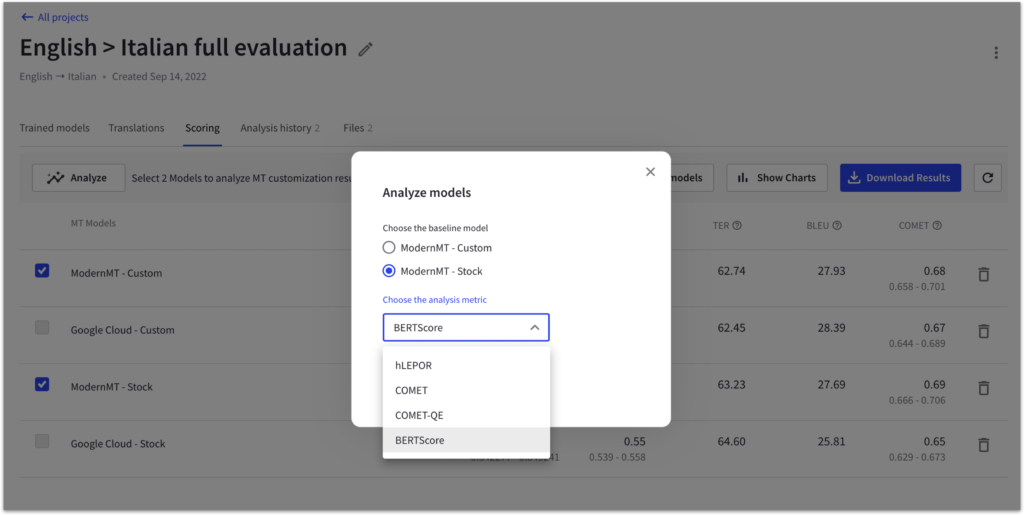
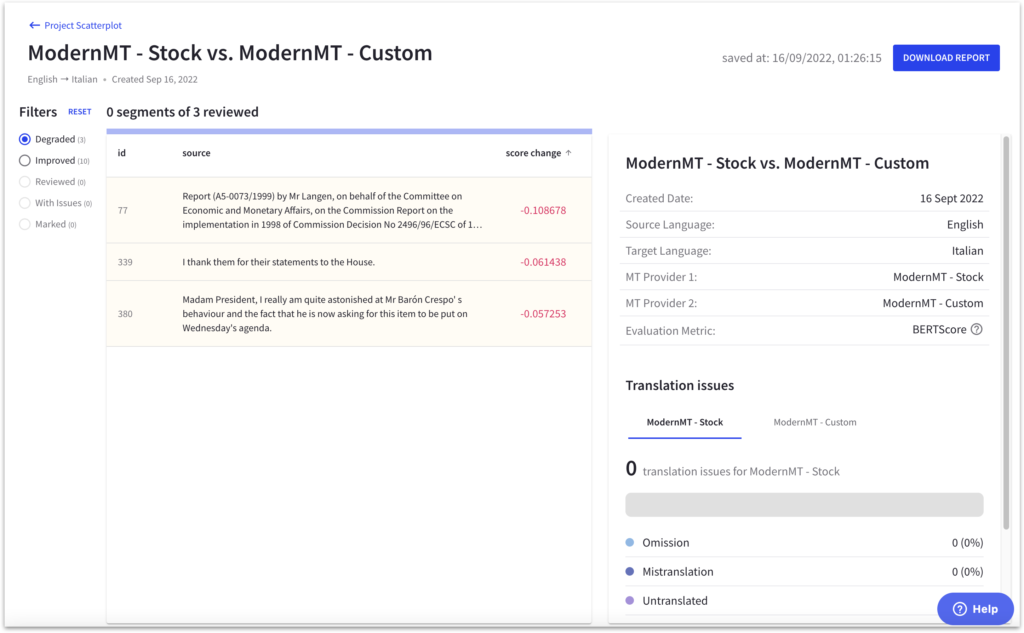
We usually also take a deeper look at what is behind these scores by selecting the custom model we want to compare, a baseline model for reference, and the desired score for the training analysis. MT Studio then generates a scatter plot that visually represents the performance of each model compared to the baseline.
This scatter plot provides an easy way to observe the translation quality differences between custom and baseline models. By analyzing this data, we can identify which models perform better and decide whether further optimization or improvements are needed for the custom models. This valuable insight can help us achieve better translation results tailored to specific needs.
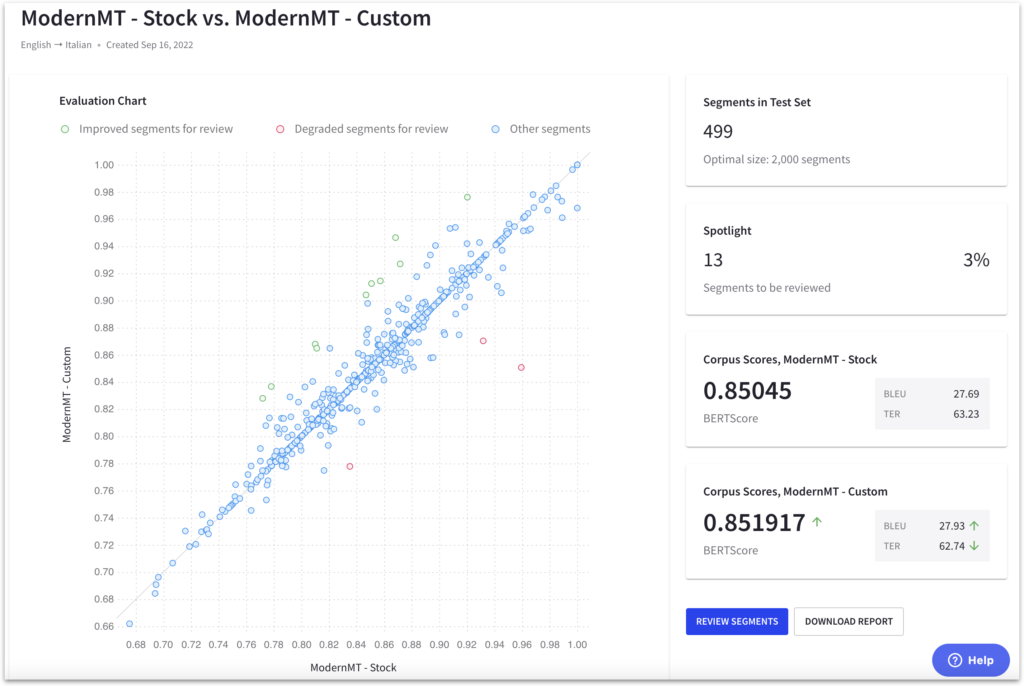
In the scatter plot, if a data point is above the diagonal line, it indicates an improvement in the score compared to the baseline model. Conversely, if a data point is below the diagonal, it signifies a decrease in the score. The average score for the custom model is greatly influenced by the most distant segments from the diagonal line.
If the score did not improve significantly for a model, the segments below the diagonal are likely the cause. Intento MT Studio allows our team to examine these specific segments, providing insight into areas where the model underperforms compared to the baseline. By analyzing these segments, we can identify opportunities for further optimization to enhance the custom model’s overall performance.
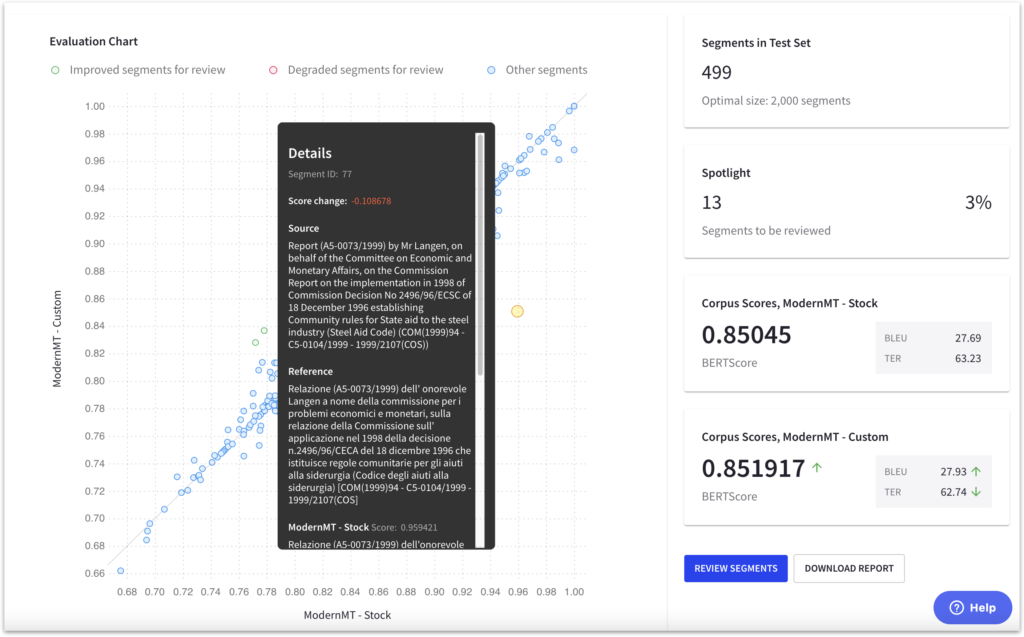
Examining the details of segments with decreased scores may help analysts understand the reasons behind the decline. They can request that language reviewers assess these segments and provide comments or feedback on the quality of the translation. This information can then be forwarded to the machine translation provider.
By communicating this feedback to the MT provider, they can better understand the specific issues affecting that particular case. This collaboration enables both parties to work together in addressing the underlying problems, ultimately leading to improvements and optimizations in the custom translation model. Such a targeted approach can help ensure that the custom model consistently achieves high-quality translations across various content types.
Glossary adaptation. Google Cloud. Configuration
Whether you have enough training data or not, you could improve the quality of MT even more by using glossaries.
To use a glossary with your custom translation model, follow these steps:
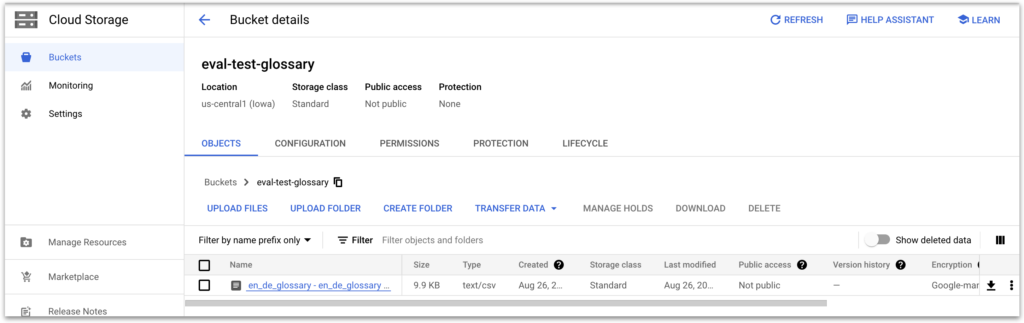
- Create object storage and a bucket: Use the platform’s user interface (UI) to set up and create a new storage bucket.
- Upload the glossary: The following steps require using an API. With the command line API tools, upload your glossary in a TSV, CSV, or TMX format to the storage bucket you created earlier.
After completing these steps, your glossary will be available for translation tasks. You can access it through the API or the platform’s console. By incorporating a glossary, you can ensure that specific terminology is consistently and accurately translated across all your projects, enhancing the overall quality of your custom translation model.

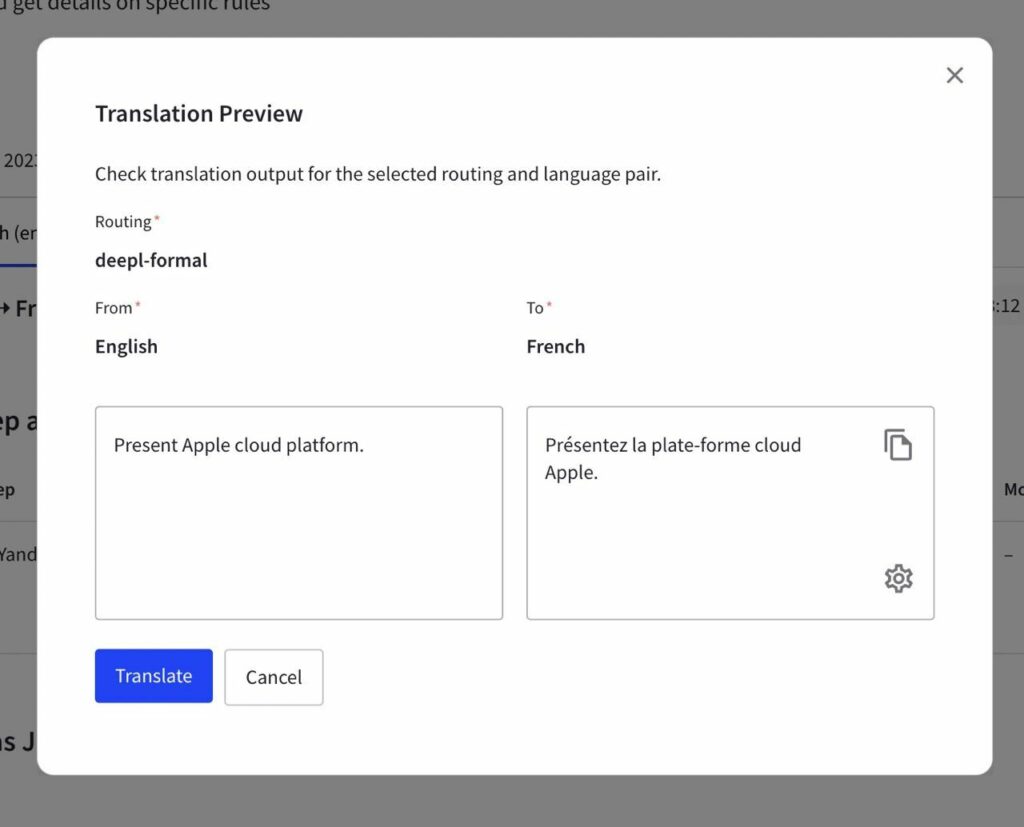
Once you have added the glossary through the API, Google provides two translation results: one with the glossary applied and the other without it. This allows you to compare the translations and assess the impact of using the glossary on translation quality.
Consider that updating the glossary can lead to downtime, as it typically requires you to delete the existing glossary, update it, and then add it again. To minimize downtime, Intento uses a green-blue deployment scheme. This approach involves creating a shadow copy of the glossary, updating it, and adding it to the system without disrupting the translation process.
Using the green-blue deployment scheme ensures seamless integration of updated glossaries, allowing you to maintain consistent and accurate translations while avoiding potential disruptions to your translation workflows.
Glossary adaptation. Other platforms and considerations.
Various machine translation providers support glossaries, though they may differ in glossary types, features, and limitations. Some providers, like DeepL and SYSTRAN, support morphology, while others may impose size limits on glossaries, which can be an issue for companies with large glossaries. Intento offers an on-the-top glossary search and replacement feature that can handle glossaries of any size.
Here is an overview of some popular providers’ glossary capabilities and limitations (as of 2023):
- Amazon: no morphology, limits on term length, languages, number of glossaries per region, and glossary size (10 MB).
- DeepL: morphology support, limitations on some language pairs, glossary size (5K), and special characters.
- IBM: one glossary per custom model, a limit on glossary size (10 MB).
- Google: a limit on glossary size (10 MB).
- Microsoft: dynamic or trained-in glossaries.
- Systran: 20K terms per glossary.
When selecting a machine translation provider, consider the glossary features and limitations that best align with your company’s needs, ensuring that your translations are consistent and accurate.
Intento glossary management.
Intento simplifies using a single glossary across different machine translation providers. You can create, edit, and add glossaries to your MT configurations in the user interface. Behind the scenes, Intento compiles glossaries to meet the specific requirements of each provider. To avoid downtimes during glossary updates, Intento employs the green-blue deployment scheme.
For providers that support glossaries, such as Google and DeepL, Intento utilizes their built-in glossary features. For other providers without native glossary support, Intento implements glossaries on top of the translation using their proprietary technology.
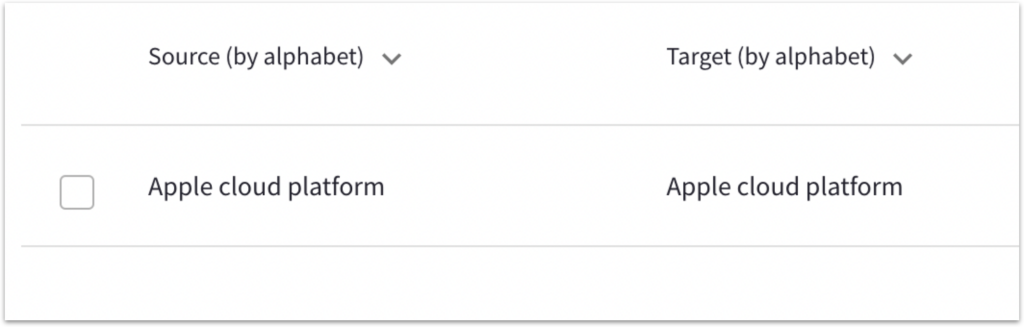
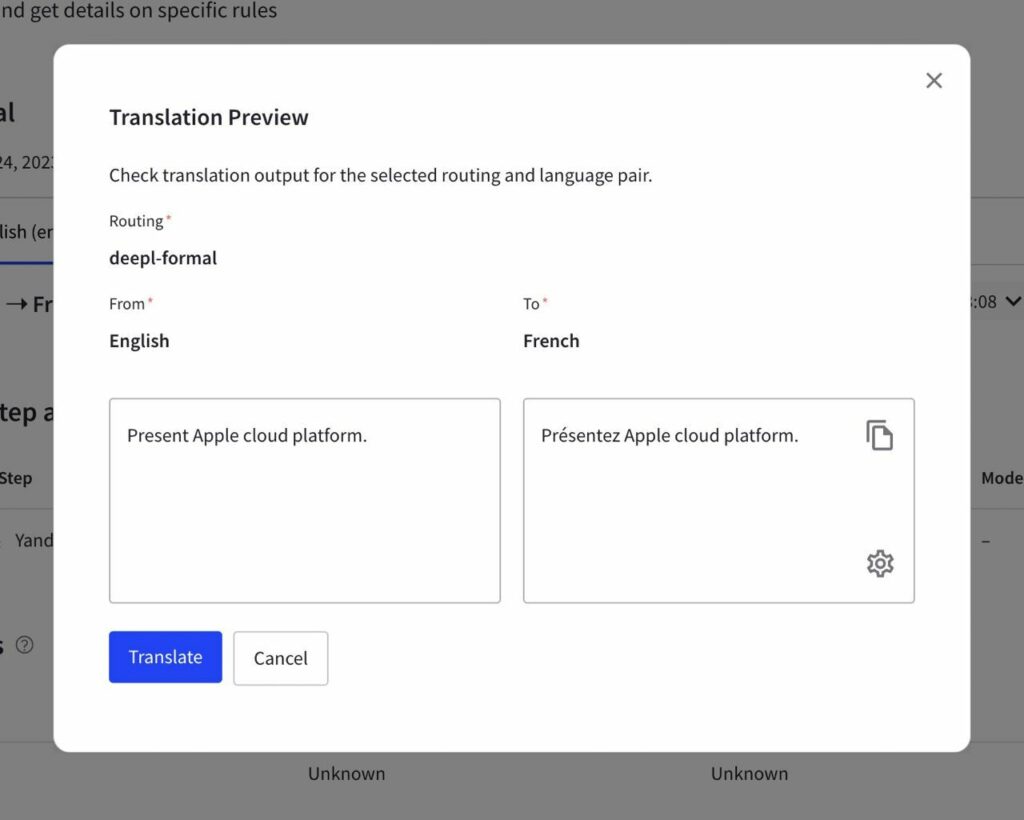
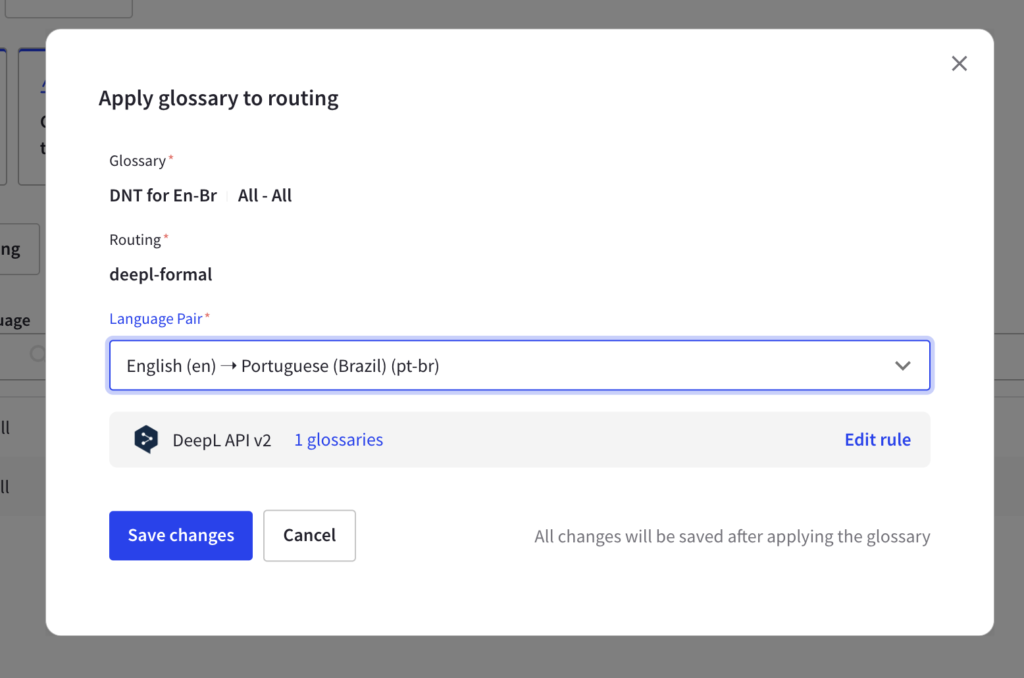
Once the glossary is added to your MT configuration, your translations will adhere to the terminology specified in the glossary.
Key takeaways
- Understanding the training and evaluation processes in machine translation systems is crucial for achieving high-quality translations. Do not rely on MT quality scores only. Following proper processes and guidelines can help prevent issues.
- Custom machine translation platforms allow users to train and optimize their models while incorporating glossaries for consistent terminology. Consider the differences in dataset requirements, types of adaptation, model updating methods, and migration capabilities when choosing a platform.
- Use valuable tools for streamlining the training and evaluation of custom machine translation models across multiple vendors. Run side-by-side comparison of stock and custom models, to get insights into translation quality improvements and areas for potential optimization.