
MT Evaluation Goals
Evaluating machine translation may appear to be solely focused on determining translation quality, but there is more to it than that. The chosen models must be approved by various departments, including security, legal, and procurement, ensuring they meet all requirements.
To effectively evaluate MT engines, know why you are using MT and what you hope to achieve. Here are some common goals for MT evaluation:
- Selecting the best MT model: Pick the most suitable machine translation model that aligns with your domain, language pair, and content type for optimal results.
- Gathering data to enhance MT and identifying bottlenecks: Collect relevant data to improve MT performance and identify areas of improvement, ensuring a smoother translation process
- Assessing risk factors: Identify potential risk factors associated with implementing MT, such as data security, to mitigate any negative impact on your project.
- Evaluating the source content’s compatibility with MT: Assess how well your source content aligns with MT capabilities, making any necessary adjustments to ensure a seamless translation
- Gaining end-user trust and confidence: Foster confidence in end-users by collecting their feedback and demonstrating the effectiveness of your chosen MT solution.
- Establishing fair machine translation post-editing (MTPE) rates: Measure machine translation post-editing (MTPE) efforts to set reasonable rates to compensate editors for their work
- Implementing translation triage: Apply a translation prioritization system to allocate resources effectively, ensuring high-quality translations for the most critical content
- Estimating return on investment (ROI): Calculate ROI for your MT project, considering cost savings, improved efficiency, and overall translation quality.
MT ROI Framework for Localization Use-Case
In this section, we will focus on the post-editing case of the MT ROI Framework. There are two approaches to evaluation: automatic and human evaluation.
MT Evaluation Types
- Automatic Evaluation:
- Reference-Based Scoring: Compare MT output to a human-generated reference translation, gauging translation quality through quality metrics.
- MTQE Scoring: Use Machine Translation Quality Estimation (MTQE) metrics to predict translation quality without a reference.
- Human Evaluation:
- Linguistic Quality Assessment (LQA): Conduct LQA to measure post-editing effort and translation quality by translators and editors, considering factors such as accuracy, style, and consistency.
- Holistic Evaluation: Gather feedback from end-users who assess the overall translation quality.
Human evaluation is often considered the benchmark for determining translation quality. Human evaluators possess linguistic and cultural expertise, enabling them to comprehend nuances, idiomatic expressions, and context-specific meanings in both the source and target languages. Human evaluators can identify subtle errors or inconsistencies that automated evaluation methods might overlook.
However, human evaluation is labor-intensive and time-consuming, particularly when examining thousands of content segments. Human evaluators can only review some small parts when the vast content requires their attention. Consequently, evaluators often use sampling, selecting a subset of content for assessment. While this method can save time and resources, random sampling represents only some of the content adding the risk of missing business-critical errors.
We combine automatic and human evaluation, using smart sampling to make the process reliable, directing reviewers’ attention to the most relevant segments. Smart sampling guarantees critical information and context-specific nuances are captured, leading to more accurate and reliable translation assessments. This ensures that the effort spent evaluating 1,000 words represents the effort required for half a million words in production.
The primary objective is to reduce the content review volume by approximately 200 times, which correlates with reducing review time.
Translation quality scores (metrics)
Translation quality scores are numerical values assigned to machine-translated content to measure how close the translation is to a “golden” reference. There are several ways to calculate them:
- Corpus-based scores (e.g., BLEU): Non-comparable across datasets, unstable at the segment level, and do not provide statistical significance
- N-gram-based scores: Do not tolerate alternative translations
- Embedding-based scores: Tolerate alternative translations but may have review bias depending on training data (e.g., tone of voice preference); Some embedding-based scores are customizable
Note that scores should not be compared between languages, as they have different tokenization methods. Absolute values of scores are less important than how engines are ranked. Focus on the correlation between scores rather than their absolute values. Understanding the scoring system will help identify potential miscorrelations.
Reference-based scores
Reference-based scores compare the actual machine translation to a reference translation. There are two main types: syntactic similarity scores, primarily based on n-grams, and semantic similarity scores, which compare meaning using word embeddings. Syntactic similarity scores are less tolerant of alternative translations and less effective for languages with complex morphology. Semantic similarity scores are more tolerant of alternative translations.
Examples of reference-based scores
- hLepor (Syntactic similarity)
- Compares token-based n-grams similarity
- Penalizes omissions, additions, paraphrases, synonyms, and different-length translations
- BERTScore (Semantic similarity)
- Analyzes cosine distances between BERT representations of MT and human reference
- Does not penalize paraphrases or synonyms
- May be unreliable for specific domains and languages underrepresented in BERT
- TER (Syntactic similarity)
- Measures edits required to transform MT into reference translation
- Penalizes paraphrases, synonyms, and different-length translations
- PRISM (Semantic similarity)
- Evaluates MT as a paraphrase of the human reference translation
- Penalizes fluency and adequacy errors
- Does not penalize paraphrases or synonyms
- COMET (Semantic similarity)
- Predicts machine translation quality using information from both the source input and the reference translation
- Achieves state-of-the-art correlation with human judgment
- May penalize paraphrases and synonyms
- SacreBLEU (Syntactic similarity)
- Compares token-based similarity of the MT output with the reference segment; averages it over the entire corpus
- Penalizes omissions, additions, paraphrases, synonyms, and different-length translations
Read more about MT Quality metrics here.
MT Quality Estimation (MTQE) metrics
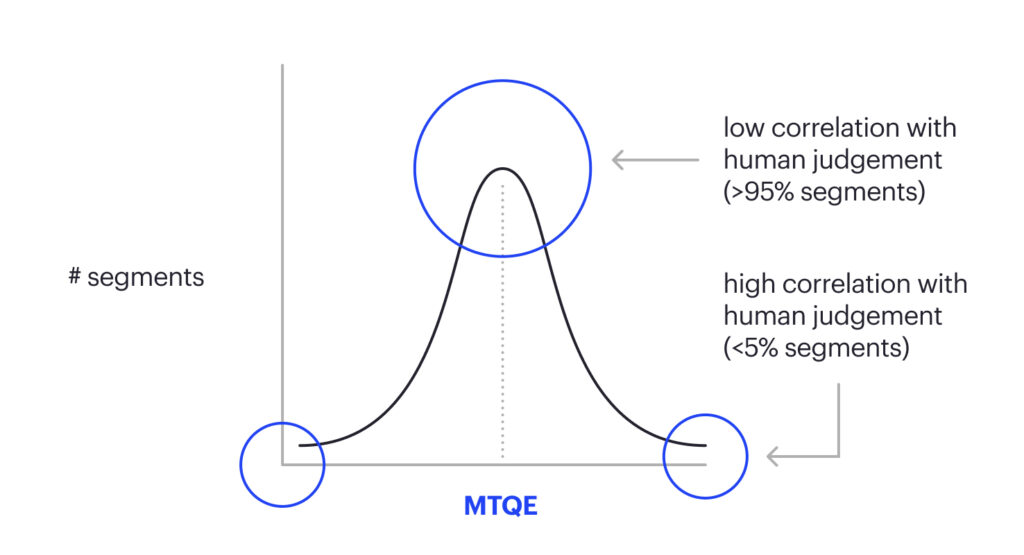
MTQE scores indicate the likelihood of a translation being correct or incorrect when you do not have human reference to compare. For this purpose, various tools and models can be used, including open-source options like LaBSE and PRISM and commercial solutions like ModelFront and COMET QE.
These scores are applicable for specific evaluation goals but not for choosing the MT model and estimating ROI, as pre-trained quality estimation models often show minor discrepancies between MTQE and LQA results. Customization of an MTQE model may help improve these discrepancies.
Nevertheless, MTQE scores are helpful for data cleaning by detecting mistranslations and directing reviewers’ attention to potentially risky content. While they may not be suitable for broader MT evaluation purposes, they can be valuable in addressing specific evaluation concerns and ensuring data accuracy, as shown in Figure 34.
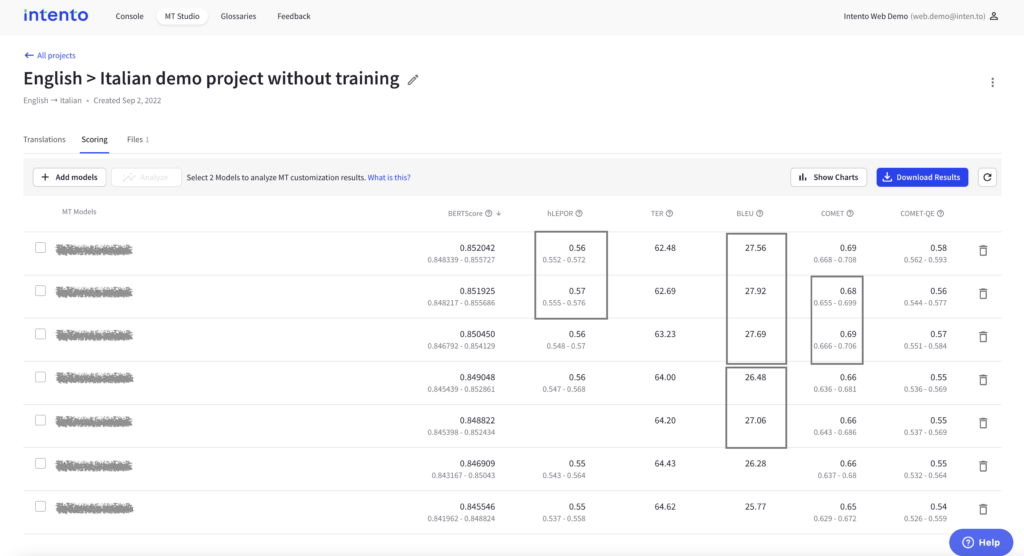
Reducing the amount of data for human evaluation using automated corpus-level scoring
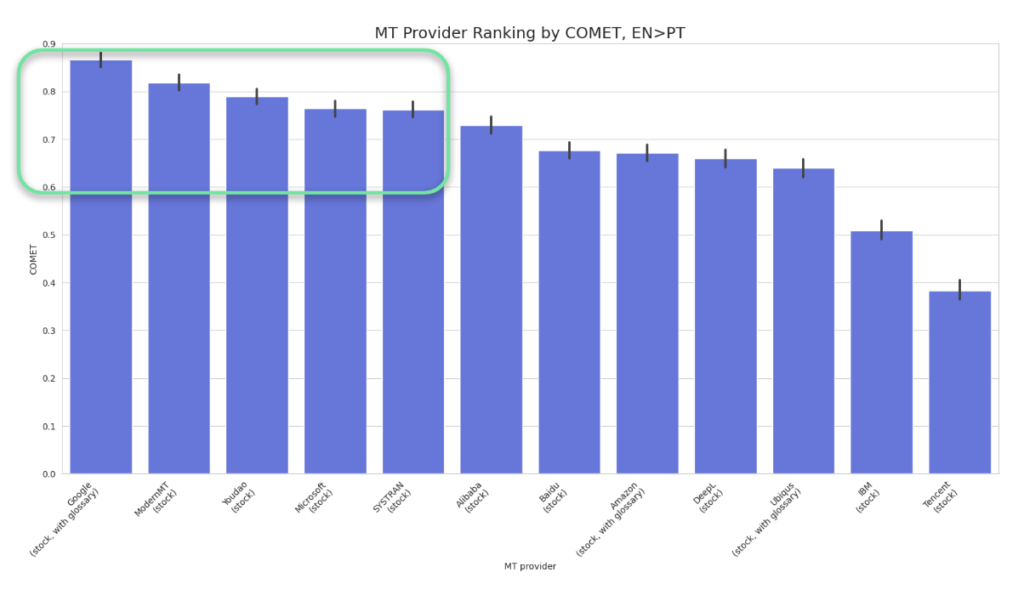
The first step in reducing data for human evaluation is to assess only the models with the highest corpus scores. Typically, this involves selecting the top three or four models or even those that are statistically significant based on their confidence intervals.
A confidence interval is a statistical measure that estimates the range within which a specific parameter or value is likely to fall. It indicates the estimate’s uncertainty and is often expressed as a percentage. A confidence interval captures the possible range of values for a given estimate, with a specified level of confidence that the actual value lies within that range.
Aspects of scoring
When using scores to evaluate MT quality, consider the following:
- Hyperparameters: Be aware of the comparability of scores across different algorithms, as they may have varying hyperparameters. For instance, BLEU scores cannot be directly compared due to differences in their parameterization.
- Scaling, Normalization, Standardization: Consider these data preprocessing techniques to ensure scores are consistent and comparable across different data sets or models.
- Absolute Scoring vs. Ranking: instead of using absolute scores, which provide a specific value for translation quality, use ranking, which orders translations based on their relative performance.
- Statistical Significance and Confidence Intervals: Evaluate the statistical significance of your results and use confidence intervals to compare mean scores, determining the reliability and validity of your translation quality assessments.
Calculating the scores. Libraries
Many MT evaluation scores can be found in research papers and open-source platforms. One method to calculate these scores uses Python packages for various metrics, such as COMET or SacreBLEU.
Intento has also implemented scores on the platform, allowing customers to calculate various scores via API. Note that for scores requiring GPU, you should manage deployment, provisioning, and de-provisioning to avoid unnecessary expenses.
Another option is Intento MT Studio, which offers a simple user interface to run translations through several stock engines and calculate scores. By leveraging these tools and resources, you can efficiently evaluate machine translation models and determine the best fit for your needs.
More on how to make sampling smart and run LQA – in the next chapter, Linguistic quality analysis and ROI estimation.
Key Takeaways
- Identify MT evaluation goals: Understand your objectives when evaluating MT engines, such as selecting the best model, improving performance, assessing risks, and estimating ROI.
- Combine automatic and human evaluation: Utilize reference-based and MTQE scoring for automatic evaluation while incorporating LQA and holistic evaluation from human reviewers.
- Sample smart for efficient evaluation: Implement smart sampling to focus reviewers’ attention on the most relevant segments, ensuring accurate and reliable translation assessments while reducing review time.
- Understanding and selecting scoring methods: Consider various scoring types, including corpus-based, n-gram-based, and embedding-based scores, as well as their limitations and benefits, to make informed decisions during the evaluation process.