

Keeping track of the machine translation landscape isn’t easy. Engines get upgraded all the time. Here you are, choosing the best MT for your content, training a custom engine to get the best results, finally making a decision — and a couple of months later, the provider rolls out an upgrade, and suddenly everything’s different. Or is it? Will the new engine give you better translations than your current one? Do you have to run a full-scale MT evaluation again?
Luckily, at Intento we have a solution that lets us run a quick comparison of two MT engines. So when Microsoft announced that they upgraded their Custom Translator’s architecture, we could immediately check exactly how significant the quality improvements would be if we re-trained one of our Microsoft engines on our specific dataset.
A little experiment with Microsoft
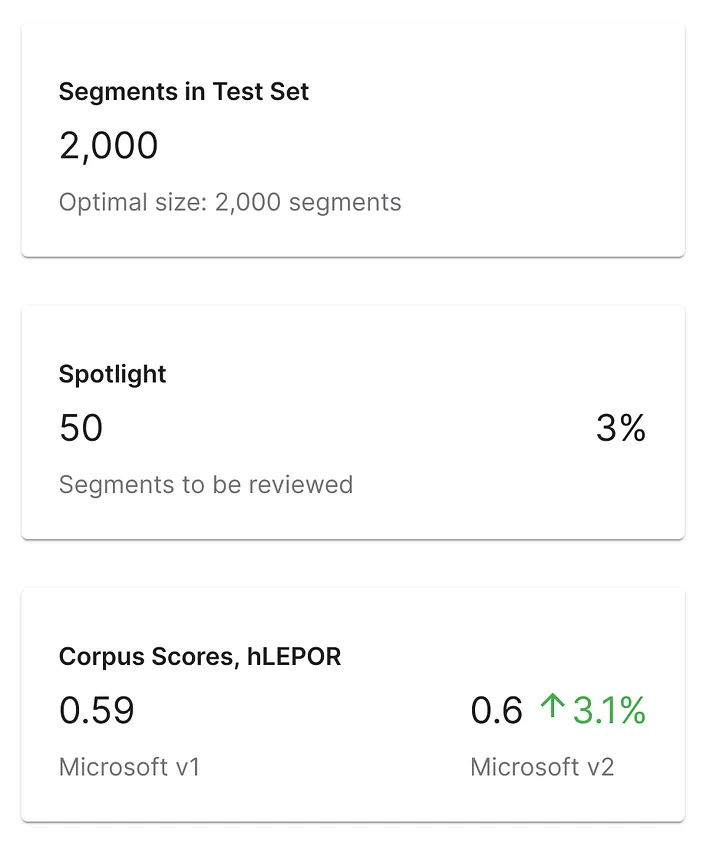
Earlier this year, we evaluated several MT engines, both stock and custom, to see how well they would translate data in the domain of COVID-19. Among others, we trained custom Microsoft engines on TAUS Corona Corpus in seven language pairs, translated test sets with these engines, and we still have those translations. We decided to see how much Microsoft’s upgraded engine would be improved for two language pairs, English to Italian and English to Simplified Chinese. All we had to do for each language pair was take our old training set and test set, train a new Microsoft engine on the training set, translate the test set with this engine, and open Spotlight — our tool for MT evaluation.
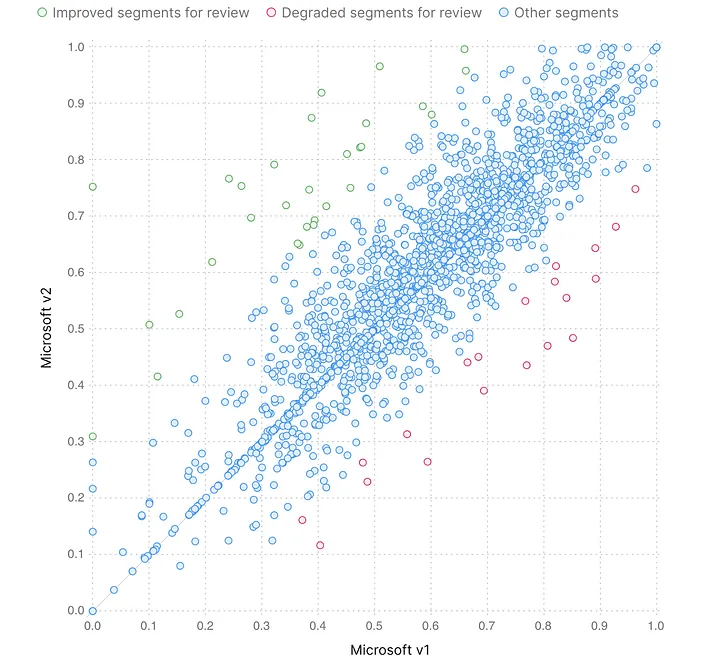
Fast forward a few hours for training new engines, a few minutes for translations, and a few seconds for computing scores in Spotlight, and we already had some preliminary results. For English to Italian, the new engine’s corpus score had grown by 3.1%. This looked promising, but we know better than to make conclusions from corpus scores only, so we looked deeper at individual text segments illustrating the most significant differences between engines.
Looking for changes
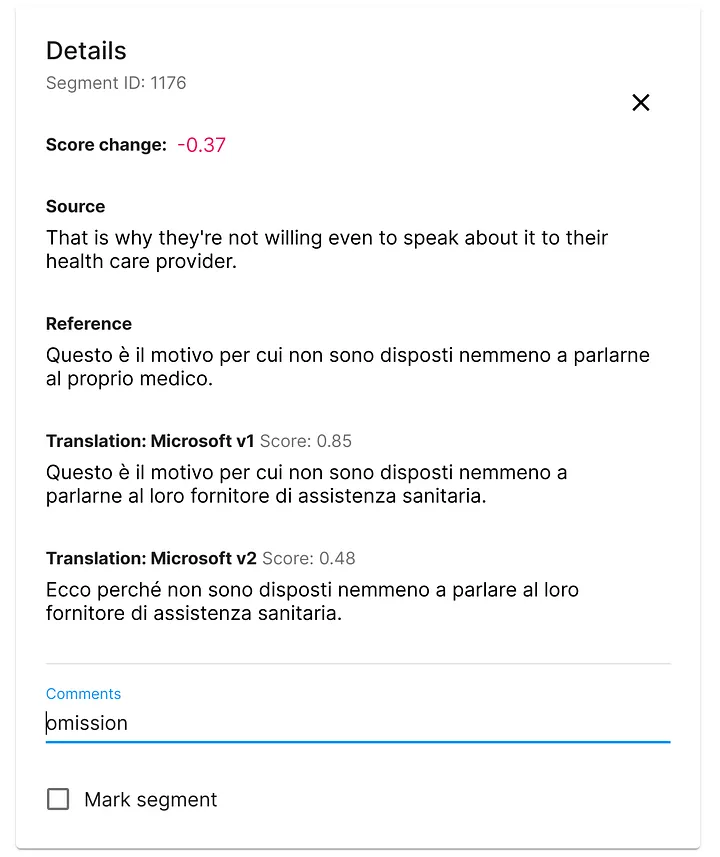
English to Italian, degraded segments
The first thing we always look for is systemic degradation: what if the upgrade has broken something? We need to see the segments for which the new engine got lower scores than the old engine. Conveniently, Spotlight brings up these segments first, and so we immediately saw two mistranslations, one omission, a corrupted medical term (could be critical in texts about COVID!), and a few other issues — but then there was also a segment that the new engine translated better though its score was lower. On the whole, these isolated quirks didn’t signal any global degradation, so we moved on to the segments whose translations have improved in the new version and saw that an ancient problem seemed to have been fixed by the Custom Translator upgrade.
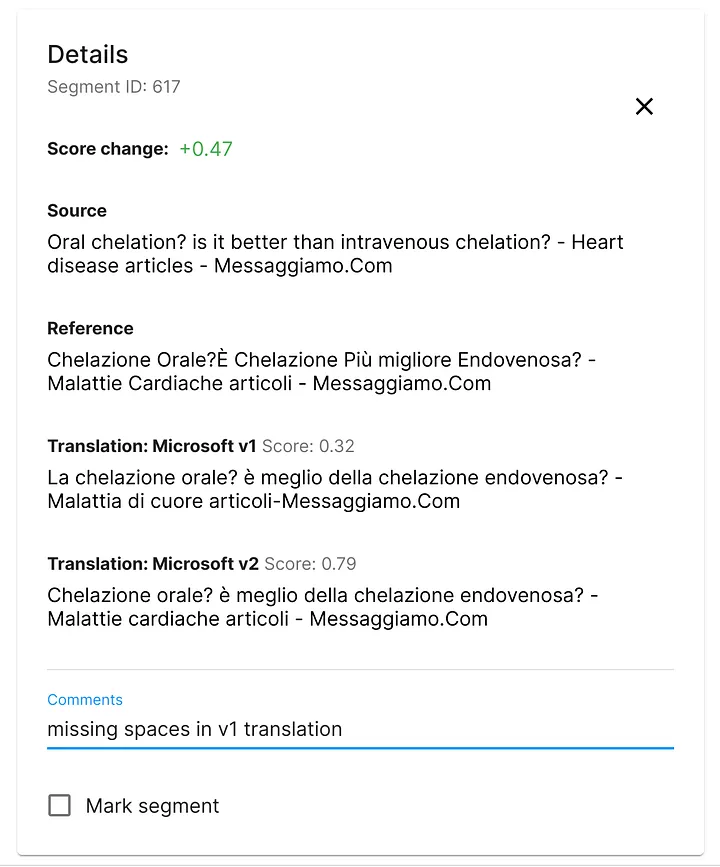
English to Italian, improved punctuation
For a long time we’d been seeing the same problem in Microsoft custom translations: spaces went missing around punctuation, like dashes, and slashes. This wasn’t really a catastrophic error, but it would often make otherwise perfect translations less readable, not to mention lower scores rather dramatically. Well, looking through old and new translations in Spotlight, we were happy to observe that the new engine doesn’t seem to have this issue anymore. Hurray for Microsoft!
The whole analysis took about 15 minutes, and the conclusion for English to Italian was that the platform upgrade led to some improvements for our data, and a long-standing issue has been fixed.
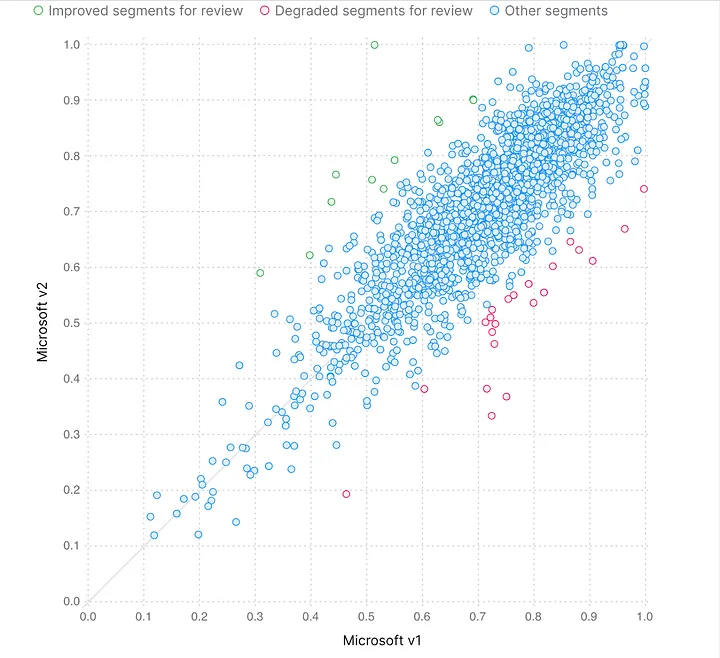
English to Chinese
Next, we repeated the process for English to Chinese.
What does it all mean for you?
What you have to understand about this little experiment of ours is that it doesn’t tell you anything global about Microsoft Custom Translator’s improvement. Is the new architecture an improvement? Why, of course, it is! You just need to know exactly how relevant this improvement is to you. Like we always say, there is no such thing as the best MT system that fits all. Results are different for different language pairs, domains, and use cases. What works great for others might not work so well for you. So when your MT provider rolls out an upgrade, you need to decide if it makes sense to switch to a new engine. If you know you’ll get a boost in quality, go get that new engine. If you see no visible change, continue with your old engine. With Spotlight, you can make an informed decision in a quarter of an hour.


