

Machine translation keeps getting better. Across enterprise solutions powered by the Intento MT Hub, we often see up to 70% of MT output accepted by professional linguists and up to 97% — by end-users. However, if you still hesitate about using MT, there is something you can do to further improve the quality of existing engines and minimize the risk of embarrassment. Go to one of those MT providers that offer engine customization, that is, fine-tuning with your own data.
Training engines on data similar to what you’ll be translating almost invariably produces more impressive results than any stock (pre-trained by provider) MT engine will produce. Where the stock engine looks at unfamiliar phrasing and terminology and makes a guess, the custom engine goes, “I’ve seen this before, I got this,” and gives you relevant translations with the correct vocabulary.
A little bit of history
Until very recently, building a custom NMT model required collecting several million segments of training data and either attracting top AI and engineering talent to train a model from scratch using one of the open-source NMT frameworks or paying a fortune to outsource it.
It all changed during 2018 when a number of MT vendors began offering domain adaptation technology. In this case, a baseline NMT model trained on billions of segments is adjusted using a little bit of in-domain data — as low as 1 segment, but most often starting from ten thousand.
Of course, 10,000 segments is far from being enough to make a backpropagation in a deep neural network. But it’s enough to give a neural network a better idea of what it is dealing with. It’s like giving a trained dog a cloth to sniff so it knows what you are looking for. Or, maybe a better analogy, it’s like onboarding a new team member. It won’t replace years of expertise, but they can be taught how to apply that expertise to a task at hand.
Let’s customize. Choosing an engine and the data you need.
What do you need to customize an MT engine? Step one, choose an engine. Not all MT providers offer customization. Of those that do, the most well-known are Google AutoML, Globalese, IBM, Microsoft, ModernMT, SYSTRAN, SDL, and Tilde. There are many differences between providers. Some only take a second to customize, while others take hours or even days. Some can add custom term bases and make absolutely sure your terminology is not mishandled. Providers have different lists of supported language pairs, and even if a provider can translate some pair, it doesn’t always support customization in this pair. Costs can be very different too, and you need to calculate the total cost of ownership carefully. And importantly, how much data do you have? By the way, this is the second step…
Data. You need parallel text segments in the source and target languages from the same domain that you’ll be translating. How many segments? We could say, “The more, the better!” — but that’s not always true. We have seen disappointing cases where customization with a million segments did not result in much improvement over the stock engine. On the other hand, one time, we fed an engine with only 5,000 segments, and it beat all the stock engines in a blind human review!
Different providers have different requirements for the minimum number of segments they need to train, ranging from 1 to 15,000. Top boundaries vary too, and, like we said, more is not always better, providers actually warn about this. Think about data quality, not only quantity. Bad training data can make customization go wrong. We had a case when there were many bulleted lists in the training data, and the custom MT started to add bullets in the results randomly.
Take a good look at your data and ask yourself some questions. Are the source and target language correct? This may sound silly, but if you confuse Slovak with Slovenian or Simplified Chinese with Traditional, your custom engine will learn to translate into a language you didn’t need. Do the target texts match the source texts? If not, the custom engine will learn weird things. Do the target texts translate terminology consistently? You can’t expect the custom engine to learn how to translate a term if it has six different translations in your training data.
To make sure nothing has gone wrong, you need — here comes step three — smart quality analysis. How do you know a custom engine has been trained nicely and will perform better than a stock one?
Let’s analyze. Did it work? The metrics to use.
Quality metrics (BLEU, LEPOR, TER, BERTScore, and many more) and visualizations give a quick idea if the custom engine is probably better or worse than the stock engine. For one thing, they let you see immediately if the engine has been trained at all: if custom translations are identical to stock ones, the engine simply has refused to be trained. Yep, that happens, we’ve seen it: it’s a bit annoying but not the end of the world; you just have to run re-training.
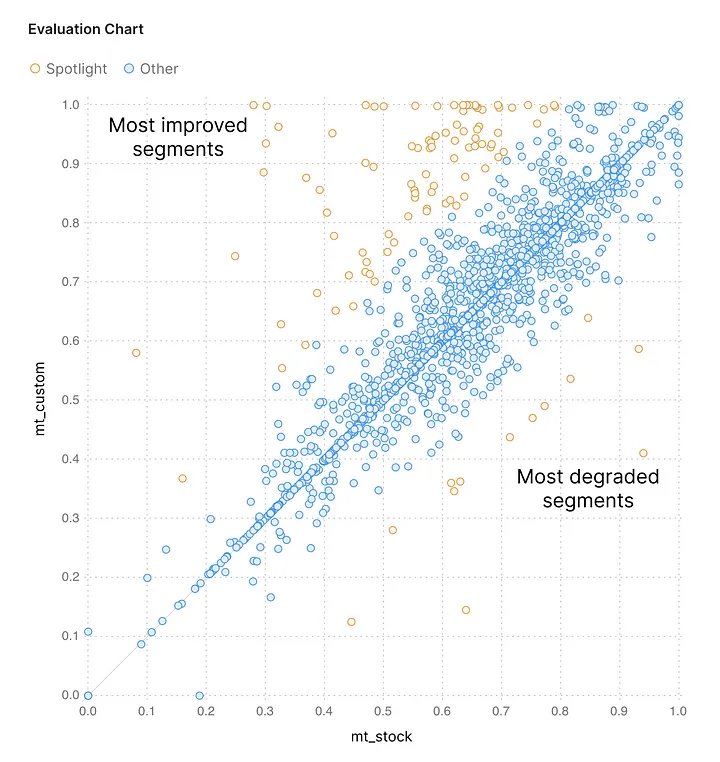
The good, the bad, and the ugly segments, as seen in Spotlight
However, be careful with metrics: higher scores don’t automatically mean higher quality, and lower scores shouldn’t immediately scare you. Maybe a segment with a lower score has issues with punctuation, that’s not really a catastrophe, right? Or maybe the segment is just an alternative, and equally acceptable, translation. Would you say that this sentence: “C’est une maladie héréditaire qui se transmet souvent des parents aux enfants.” — is a bad translation of “It is an inherited disease that is often passed down from parent to child.”? We’d say it’s just slightly different from the reference translation “Il s’agit d’une maladie héréditaire transmise du parent à l’enfant.” If you use a metric that compares the words in a machine translation to words in a reference human translation, it’ll penalize paraphrases and synonyms. Metrics that compute semantic similarity between MT and the reference translation (like BERTScore) are less susceptible to this problem.
Even if an occasional segment really is translated better by the stock engine, not the custom one, it’s no reason to panic. There will almost always be imperfect translations, but keep your eyes on the bigger picture. So the custom engine has an omission, but look, the stock engine has dozens of them in other segments. In this case, the custom engine isn’t perfect but still way better than the stock one.
However, if the custom translations have lots of bad stuff, don’t let the higher average score fool you. If every 100th translation is totally empty or complete garbage, perhaps it’s safer to stick with the stock engine, at least there will be no disasters. Of course, it depends on your usage scenario: post-edited machine translation can still be fixed by humans, but when you publish MT without any editing, avoiding critical errors is crucial, so it makes sense to play it safe and use the more reliable engine. The omission of the small word “not” in “This plant is not edible” can lead to really severe consequences.
Hurdles along the way
What if you have a custom engine with scores near 100%? Time to celebrate? Nope, time to be extra careful. Sure, this engine will shine like a star if you translate texts very similar to your training data. But one step off the beaten track and your engine might just say, “Hey, I haven’t been taught that!”, and the output will be the same as that of a stock engine, or worse.
How can you avoid trouble when customizing your MT engine? You can’t control neural MT engines’ quirks, but you do have control over what you feed them. As we said, more data is not always better: training on a huge openly available corpus won’t make a stock engine better because, most likely, it has already been trained on that. Putting together all the data you have, all the domains and styles mixed together may lead to disappointment too. If you have to choose, give the engine less, but more relevant data. And the biggest improvements usually happen in less popular language pairs: those engines benefit from even small additional training sets.
You can further enhance the output of a custom engine: use tone of voice and gender control or fix punctuation in the translation automatically to make sure your translations sound good and look professional.
Finally, remember that one day, a custom engine can outlive its usefulness. Don’t sit back and relax once you’ve trained an engine, evaluated it, and decided that you’re happy with the results. What you need to translate may change over time, so the custom engine will no longer be relevant. Or the stock engine might become so good that it’ll outperform the custom one. If you stop using a custom engine, delete it. Some providers charge just for keeping an engine active, even if you’re not translating with it.
This is all very nice, but what if you don’t have any data for training? There is still a way you can improve your translations — use a custom glossary, which is a list of terms and their translations into the target language. Even some providers that don’t offer additional engine training support custom glossaries and this service is cheaper. What works best is Do-Not-Translate glossaries: they ensure that the names of organizations, products, publications, and so on are handled properly, and Donald Trump is not changed to Trunfo in the Portuguese translation.
Key takeaways
Customization really makes MT engines produce more accurate, fluent, faithful, and domain-relevant translations. If you have at least some data, try it — even a few thousand good parallel segments can make a difference.
Do smart performance analysis before using the custom engine and don’t rely on scores alone: a custom engine with a high average score can still have critical issues. Check that your custom engine really is better than the stock one. At Intento, we have a special tool — Spotlight — for catching significant differences in translations and focusing the attention of human reviewers on translation issues that really matter. We use it right after training the engine, because the earlier you discover mistakes, the less they cost you.
And remember, if there is no perceptible difference in quality, there is no need to pay more for a custom MT engine.


