We’ve conducted multiple studies on the performance of modern Generative AI models in machine translation (MT) tasks. Our latest research assessed GenAI models from various providers, such as OpenAI’s GPT series, Google’s PaLM 2 and Gemini, Anthropic’s Claude, and Meta’s LLaMa 2.
Although many GenAI models excel in MT and can occasionally outperform traditional MT providers, there are instances where traditional MT can enhance GenAI outcomes.
Main findings
- OpenAI GPT 3.5/4 and Anthropic Claude excel at summarization in the languages we tested, without needing to switch to English through machine translation (MT).
- For AI21 Jurassic-2, META Llama-2–70b-chat, and Google PaLM-2, using MT to switch to English significantly increases accuracy, by up to three times.
- MT enhances Llama-2–70b-chat’s performance, making it comparable to leading models like GPT-4 and GPT-3.5-turbo.
- Switching to English reduces the number of critical errors when summarizing text.
- In the languages we tested, the tokenization burden didn’t make using GenAI with MT more cost-effective.
Read on to delve deeper into this study, starting with our rationale for carrying out this research, our goals, our research approach, and the results.
Research motivation
Dataset imbalance
Datasets are overwhelmingly in English, making it the predominant language in many datasets for training large language models (LLMs).
Take, for instance, the language distribution in the PaLM 2 model’s training dataset. The graph shows that English and a few other major languages make up the bulk of the dataset, with all other languages representing a tiny fraction.
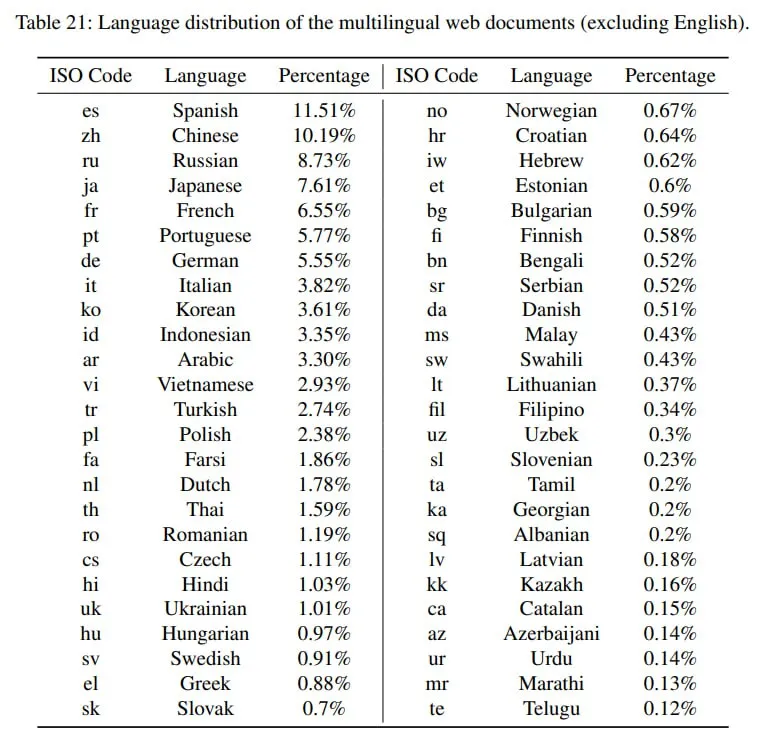
Image from PaLM 2 Technical Report
This issue is even more pronounced in the LLaMa 2 model.
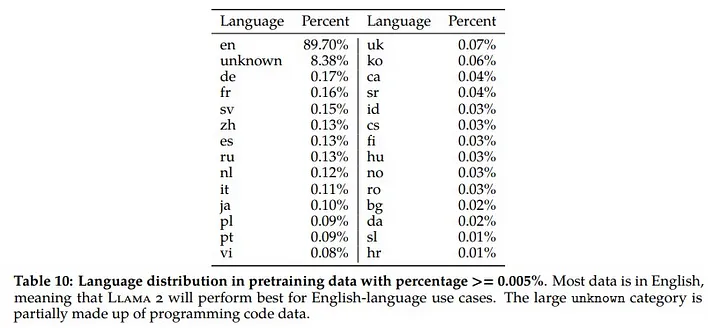
Image from the paper “Llama 2: Open Foundation and Fine-Tuned Chat Models”
Therefore, it’s reasonable to expect that LLMs perform better on tasks in English than in other languages, particularly low-resource languages.
In 2023, a study titled “Do Multilingual Language Models Think Better in English?” was published.
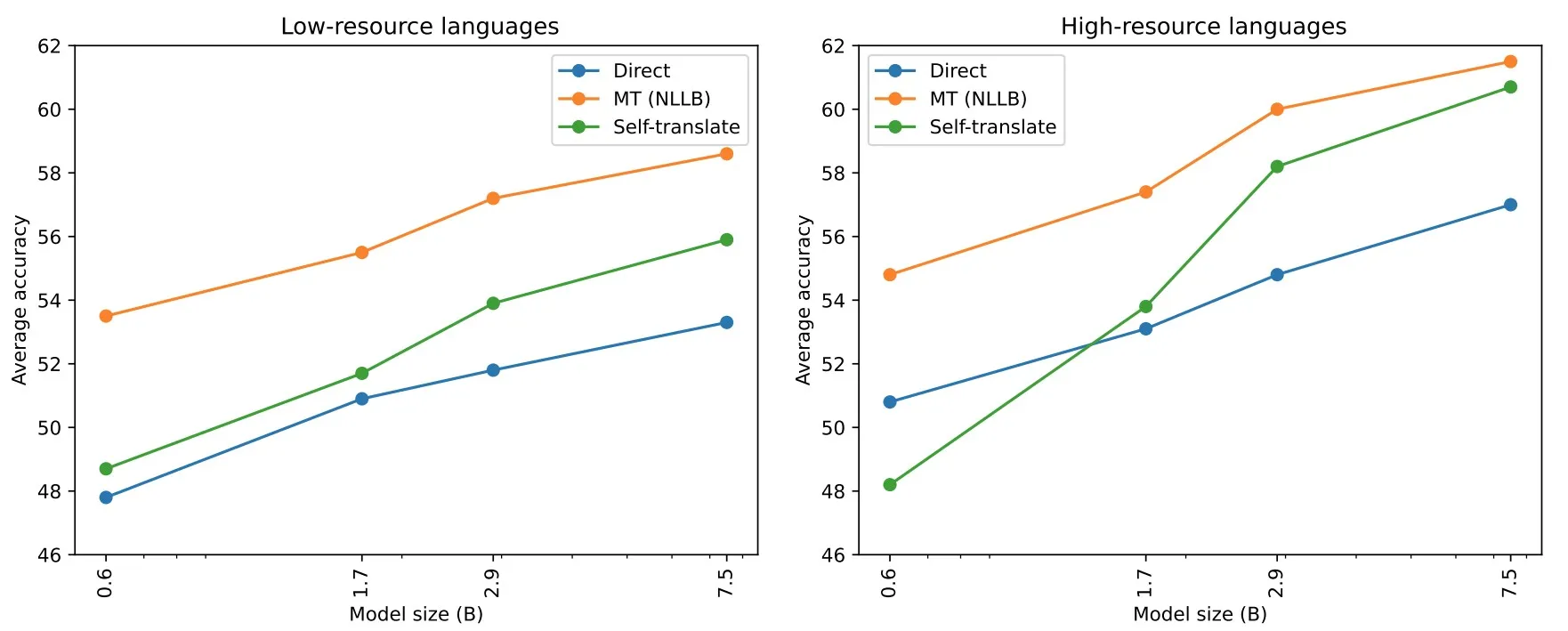
Image from the paper “Do Multilingual Language Models Think Better in English?”
The authors showed that combining machine translation (referred to as “Direct” in their graph) with LLMs enhances performance on language tasks. Another notable strategy, dubbed “Self-translate” in the study, involves using the same LLM to translate the text before tackling the task. This method also boosts performance, though leveraging a dedicated machine translation (MT) engine yields superior results.
For their research, they utilized a small, 3.3 billion parameter NLLB-200 open-source model for translation. The outcomes could potentially be even more impressive with a commercial, top-tier MT system.
Tokenization
One key point is that Large Language Models (LLMs) work on a token basis, and tokenization varies across languages. This means the same text can generate a vastly different number of tokens in different languages, even if the symbol count doesn’t vary much. For a deeper dive, check out “Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models”.
In some cases, using non-English prompts and responses can lead to up to 18 times more tokens, increasing costs, causing delays, and reducing the maximum text size. For example, an English text might yield 19 tokens, while the same text in Korean generates 97 tokens (5x), and in Malayalam, 339 tokens (18x).
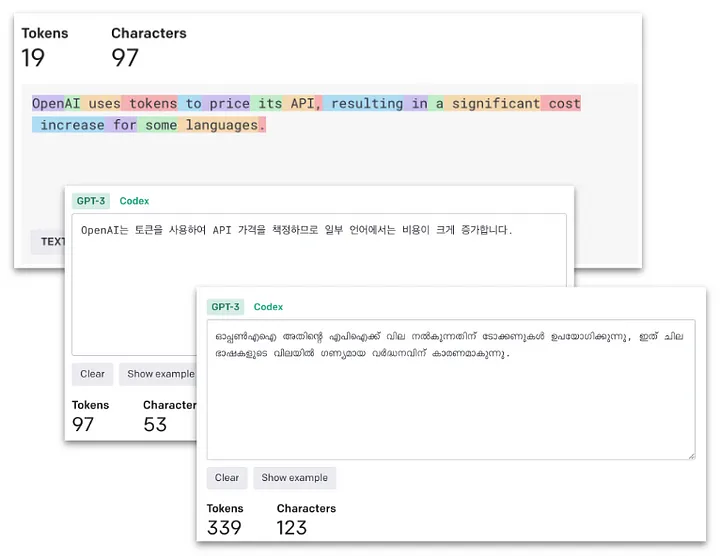
• • •
This prompted us to conduct our research on commercial GenAI models.
Research goals
We explored these questions:
- Do GenAI models perform equally well in solving language tasks (such as summarization) in English compared to local languages?
- Does the language of the prompts, English or a local language, affect performance?
- Can GenAI performance be enhanced through the use of machine translation (MT)?
- What are the cost implications?
These objectives define our study.
Note: We did not investigate GenAI’s translation capabilities, as we have previously covered this topic.
The approach
- Select a widely-used language task with robust multilingual datasets/benchmarks (we’ve selected the summarization task and the XL-Sum dataset).
- Choose the correct prompts (this is crucial).
- Consider a few languages and few LLMs.
- Consider three settings: (1) English prompt + local content (default), (2) Local prompt (via MT) + local content, (3) English prompt + English content (via MT).
- Use relevant accuracy metrics (Rouge-L).
- For each language and LLM, perform the summarization task and calculate the scores.
- Compare the accuracy and cost differences between using GenAI and GenAI+MT.
Below is a visualization of the three scenarios we’re examining:
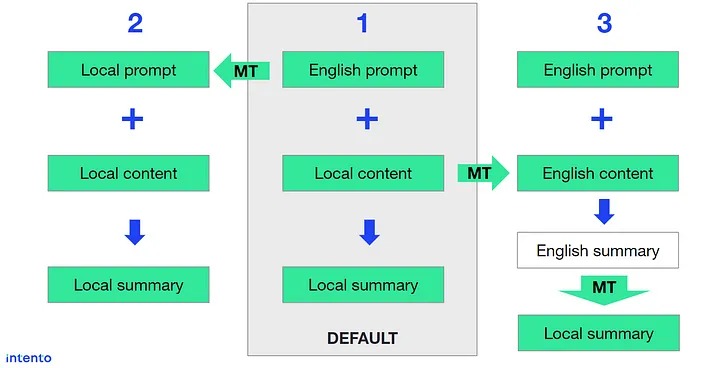
Experimental setting
GenAI models
- GPT-3.5 Turbo (gpt-3.5-turbo-0613)
- GPT-4 (gpt-4–0613)
- Jurassic-2 (we observed that j2-ultra model had quite many errors with status_code 524 whereas j2-mid model had less of them. Hence, we decided to use j2-mid model)
- Claude 2
- PaLM 2 (text-bison@001)
- LLaMA-2–70b-chat (we used the model through gpt-4–0613 Anyscale Endpoints).
We conducted evaluations from September 26 to October 10, 2023.
MT engines
We utilized MT engines according to our benchmark (https://bit.ly/share-mt-2023). Based on the language, we chose either DeepL or Google’s standard models.
Languages
- Spanish
- French
- Chinese Simplified
- Ukrainian
Dataset
We chose the XL-Sum dataset from the study “XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages,” published in the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021.
The XL-Sum dataset features BBC news articles, their headlines, and summaries. For our research, we sampled 300 articles for each language pair.
Before selecting data for our study, we did some basic cleaning of the original datasets, mainly removing extraneous content.
For translations to English, we used the top-performing machine translation engines as ranked in the latest Intento benchmark.
Prompts
We did some prompt engineering.
Here’s an example of prompts we used for summarizing news articles in English.
Short (*)
‘Write a concise summary of the news article provided by the user. The length of the summary should not exceed 3 sentences.’
Detailed
‘Provide a summary of the news article provided by the user. The length of the summary should not exceed 3 sentences. Ensure that the summary is clear, concise, and accurately reflects the content of the original text without omitting any important information or adding information not included in the original text.’
Chain-of-thought (CoT)
‘You need to provide a summary of the news article provided by the user. The length of the summary should not exceed 3 sentences. In order to do it, firstly extract important entities and events from the article. Then integrate the extracted information and summarize the article. The output should be only the summarized article.’
We didn’t see much difference in the outputs, so we chose the shortest prompt (*). If we noticed any problems with the model output, we made small adjustments to address those issues.
Scores
We use automatic metrics.
We’ve selected Rouge-L, Bertscore, and COMET-Kiwi as our metrics. ROUGE-L gauges the lexical similarity between generated summaries and their references using the longest common subsequence. BERTScore and COMET-Kiwi assess semantic similarity.
The effectiveness of these automated metrics heavily relies on the quality of the reference summaries. Given that these references were frequently shallow and lacked detail, we anticipate lower metric scores.
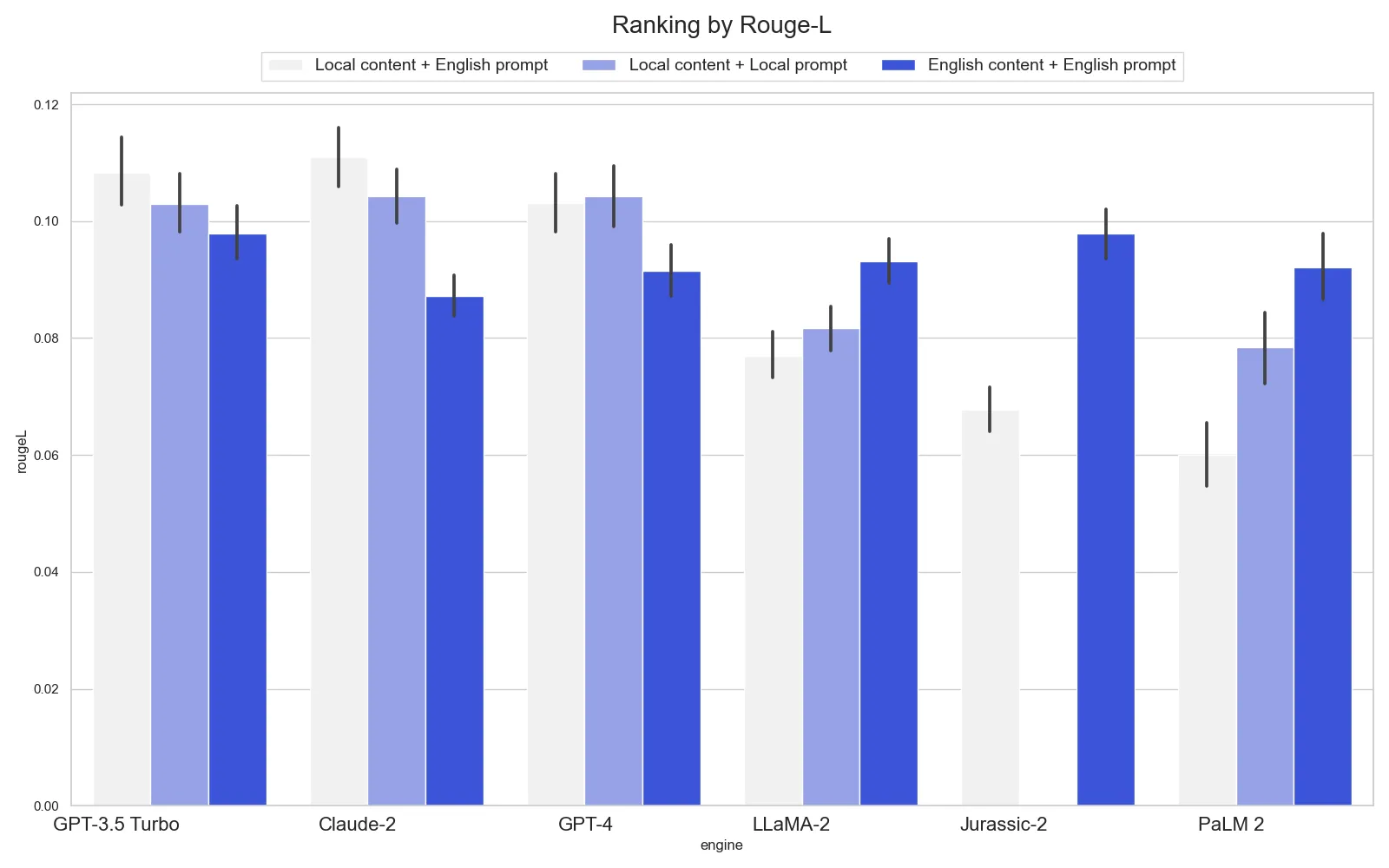
Evaluation results
In the images below, we present a distinct graph for each language. Each graph organizes results by the GenAI model across three similar settings. The first setting is our default, featuring an English prompt and local content. This is followed by a local prompt with local content, and finally, an English prompt paired with English content. Below is the legend for the graphs:

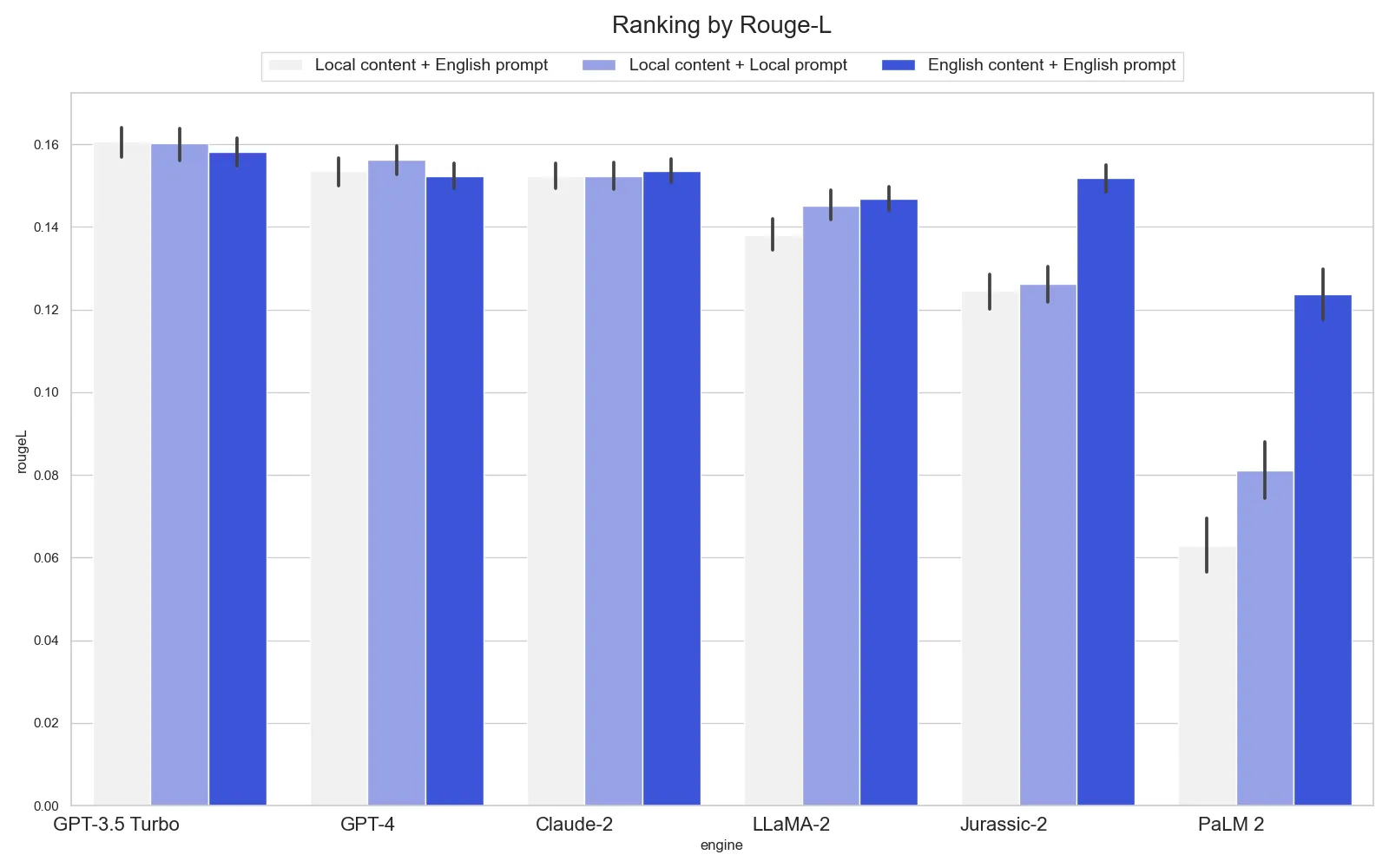
Spanish
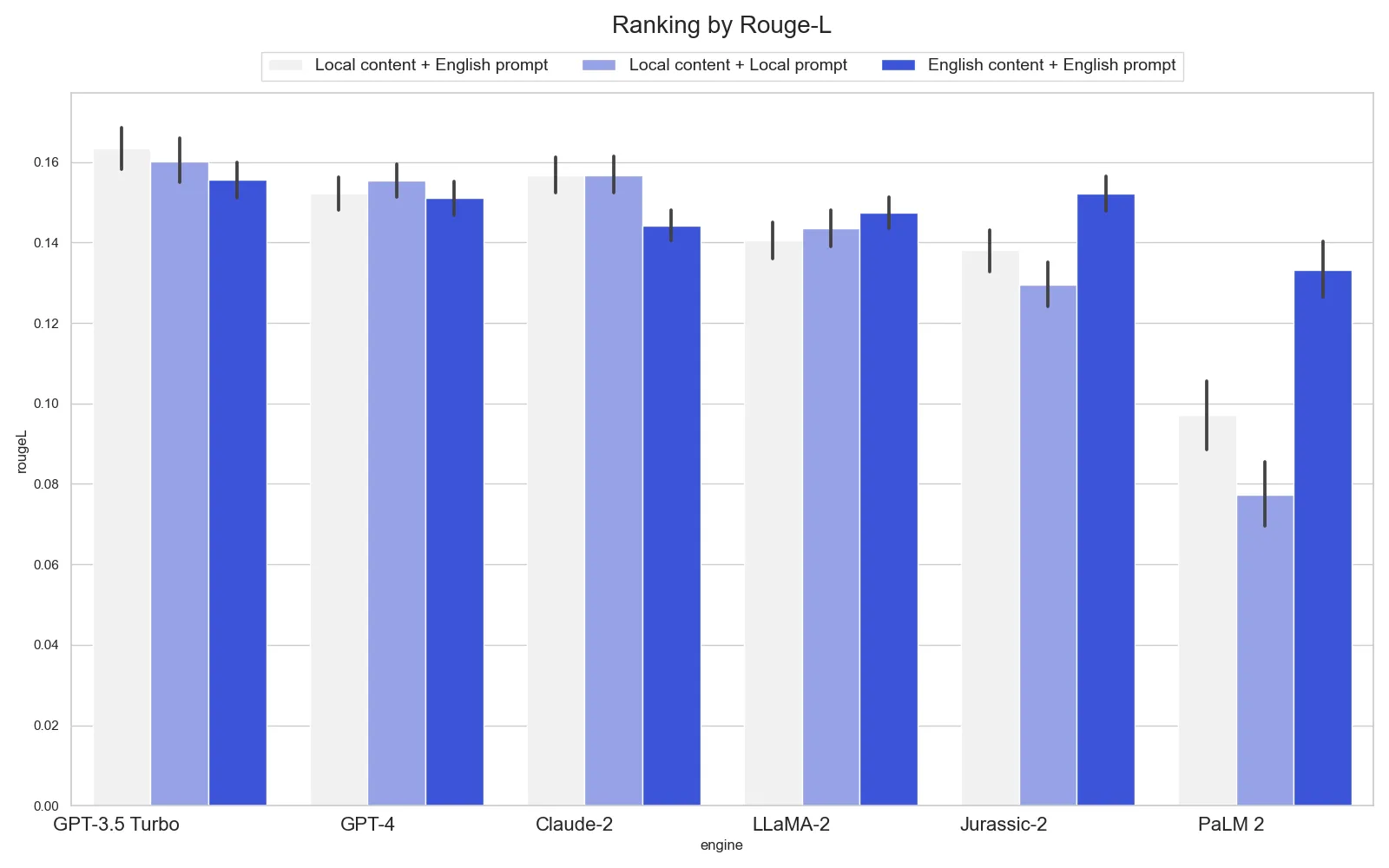
French
Simplified Chinese
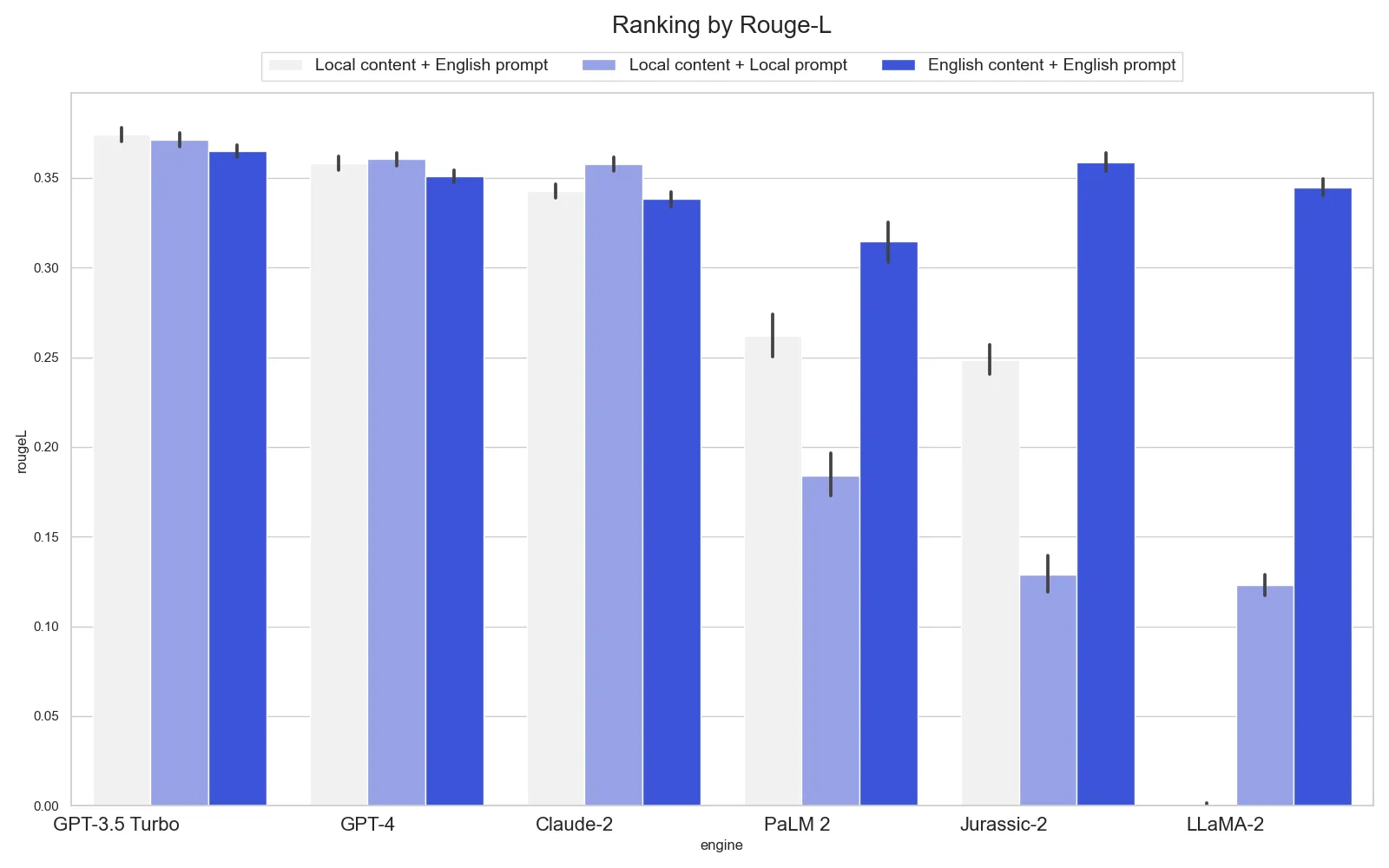
Ukrainian
Analysis
All languages and models
English content + English prompt wins on average. However, it’s significantly more expensive due to MT costs (more on that later).

Different LLMs
- OpenAI GPT-3.5/4 and Anthropic Claude-2 models work best in a default setting.
- For GPT-4 and Claude-2, settings 1–2 (with MT) either have no significant difference or make the results worse.
- For Meta LLaMA-2, AI21 Jurassic-2, and Google PaLM-2, the default setting shows the worst result, which is 20–60% worse than the best. All-English setting (+MT) boosts the accuracy up to the GPT-3.5/4 & Claude-2 level.
- PaLM-2 shows particularly low scores for Spanish, French, and Ukrainian, and LLaMA-2 refused to generate summaries in Chinese when prompted in English.
Different languages
- For Spanish, GPT and Claude perform well in any context, while other models need machine translation (MT) for accurate results. PaLM-2’s default setting yields low accuracy.
- For French, the situation is similar, but using English as an intermediary language decreases Claude-2’s accuracy.
- For Simplified Chinese, providing instructions in Chinese reduces accuracy for most models, and LLaMA won’t process Chinese requests with an English prompt. Models proficient in Chinese (GPT, Claude) experience a minor accuracy decline when switched to English, but for others, using English plus MT significantly improves performance.
- For Ukrainian, GPT and Claude show a notable decrease in accuracy when prompts are in Ukrainian or for all-English setting. Other models see a substantial improvement with an all-English setup. Some models confuse Ukrainian and Russian in their responses or address the wrong task, like entity extraction.
Significant mistakes
We examined the Rouge-L values below the first quartile.
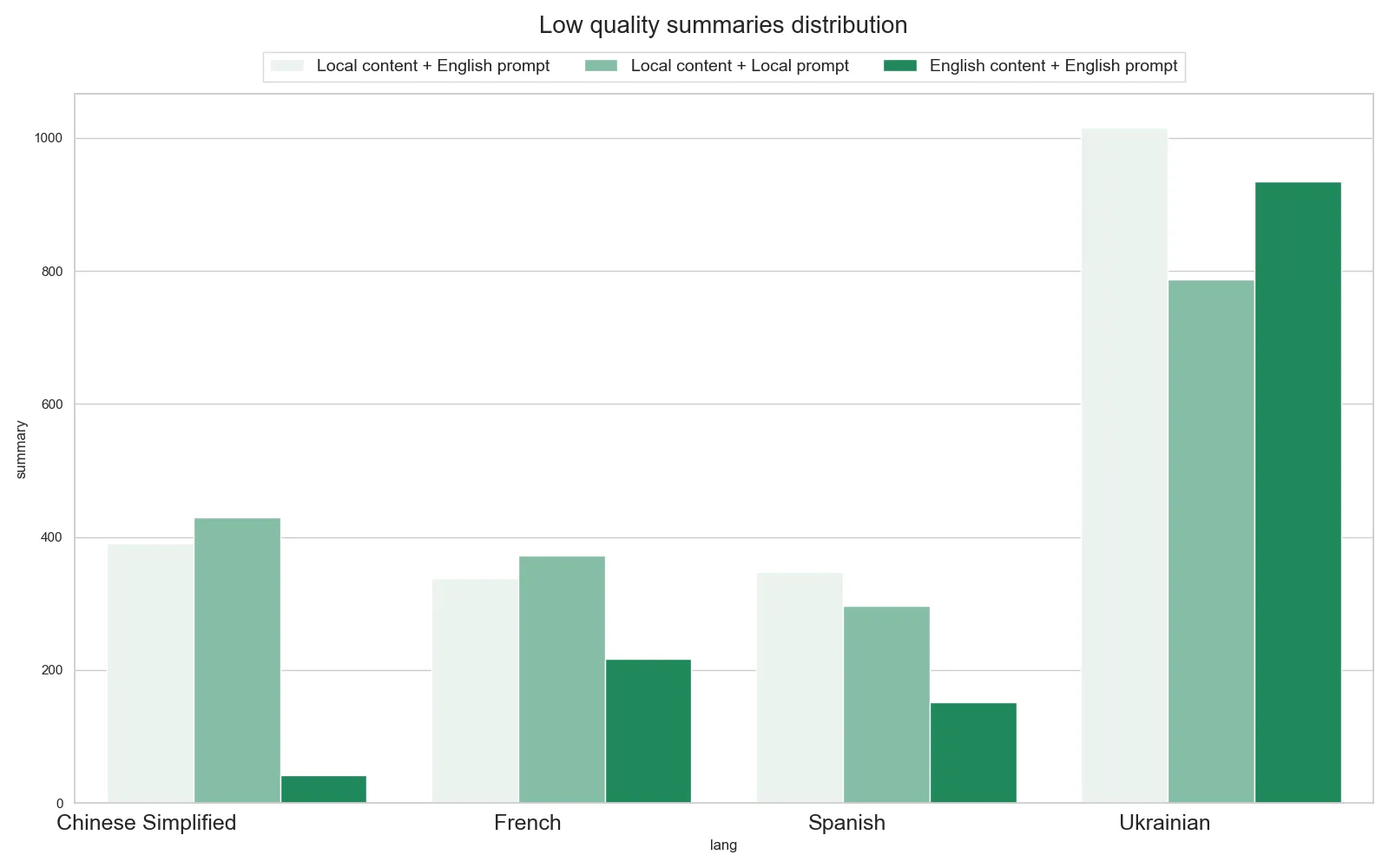
- When translating content into English, the number of critical errors in summarization typically decreases significantly.
- The only exception is Ukrainian, which tends to have a slightly higher rate of critical mistakes.
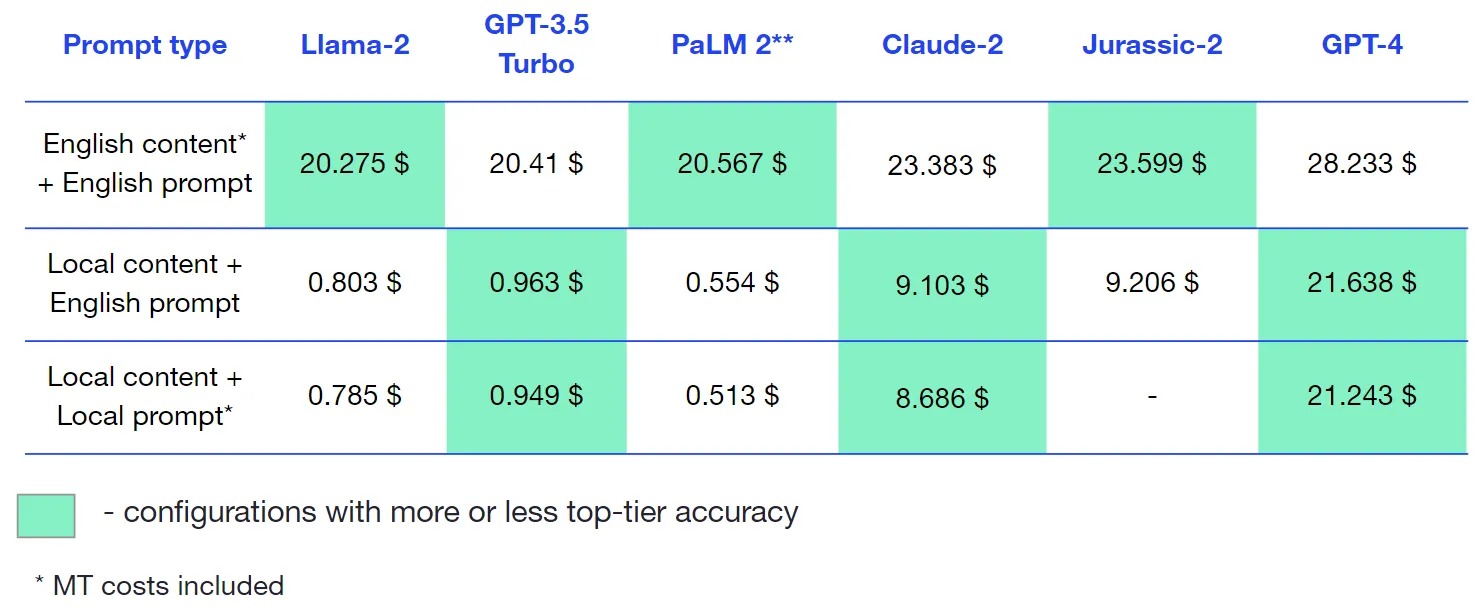
Cost analysis
Since we used Llama-2 model on Anyscale Endpoints, costs for this model were calculated using pricing on the official website.
Here’s the cost for each engine and prompt type combination per 1 million characters, including MT costs.
Spanish
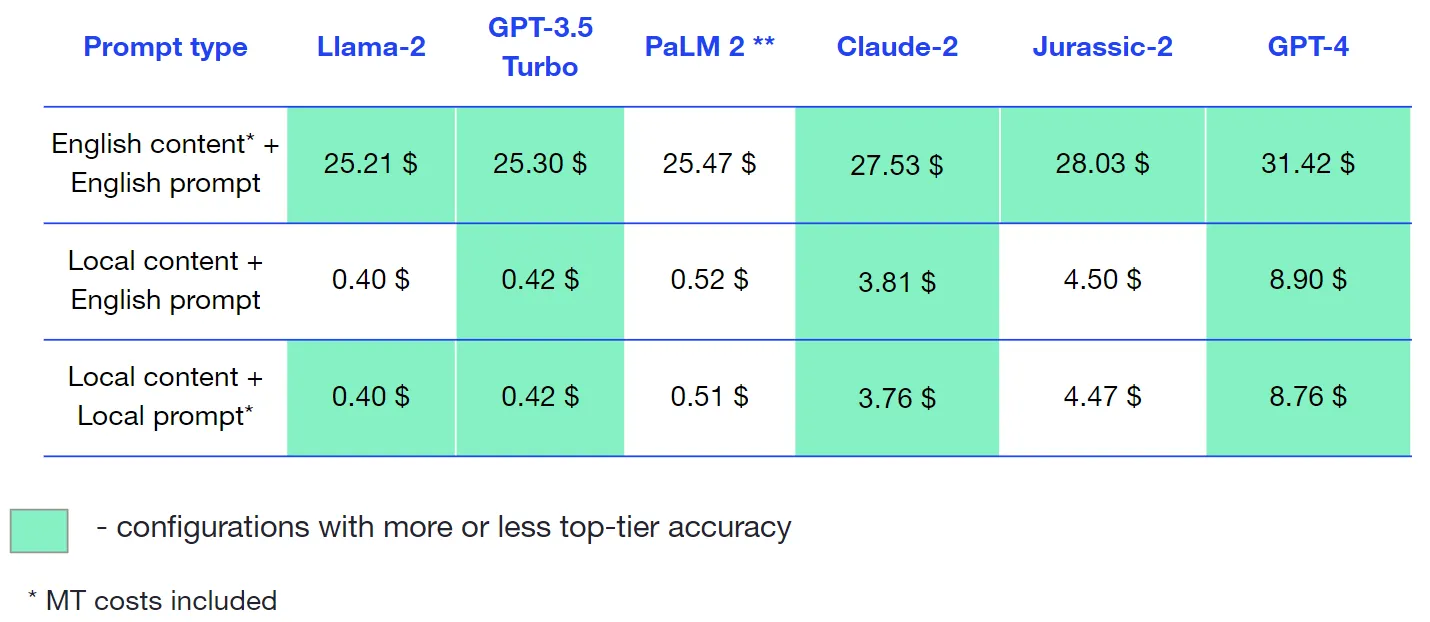
French
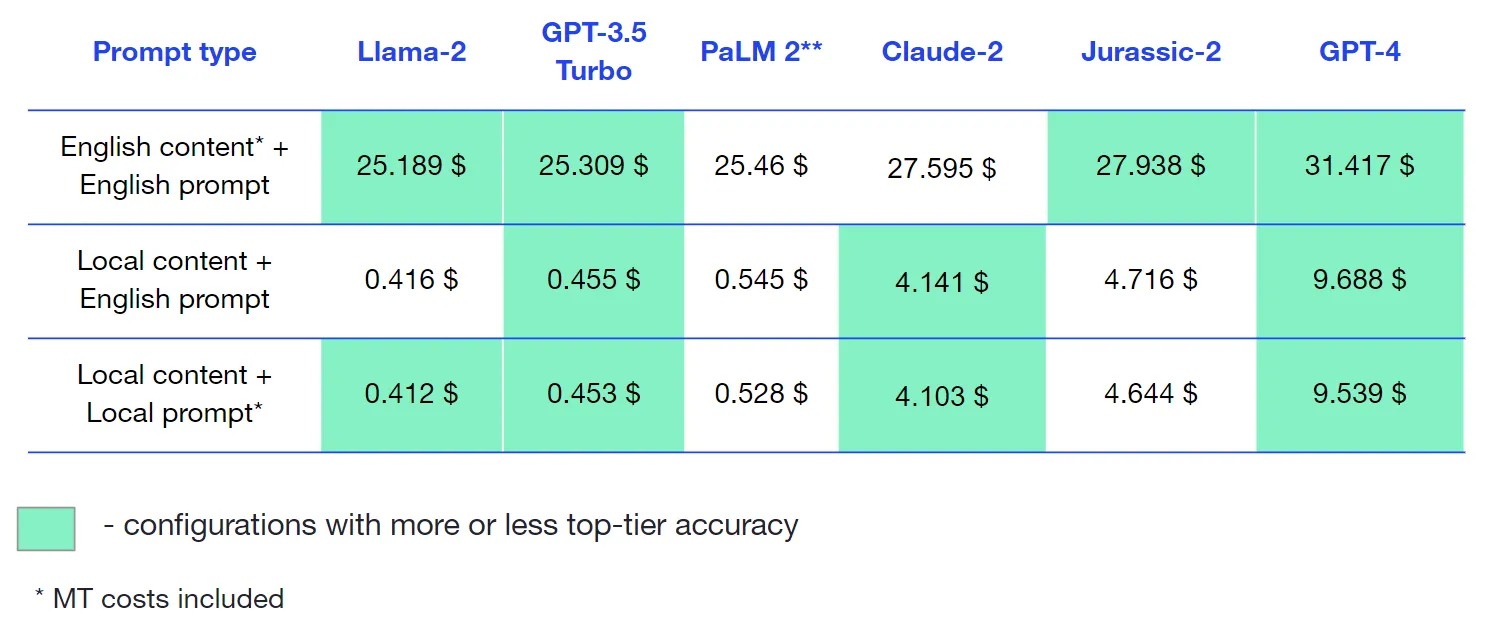
Chinese Simplified
Notice that because of tokenization, doing tasks in Chinese is expensive, but it’s still cheaper than using translation.
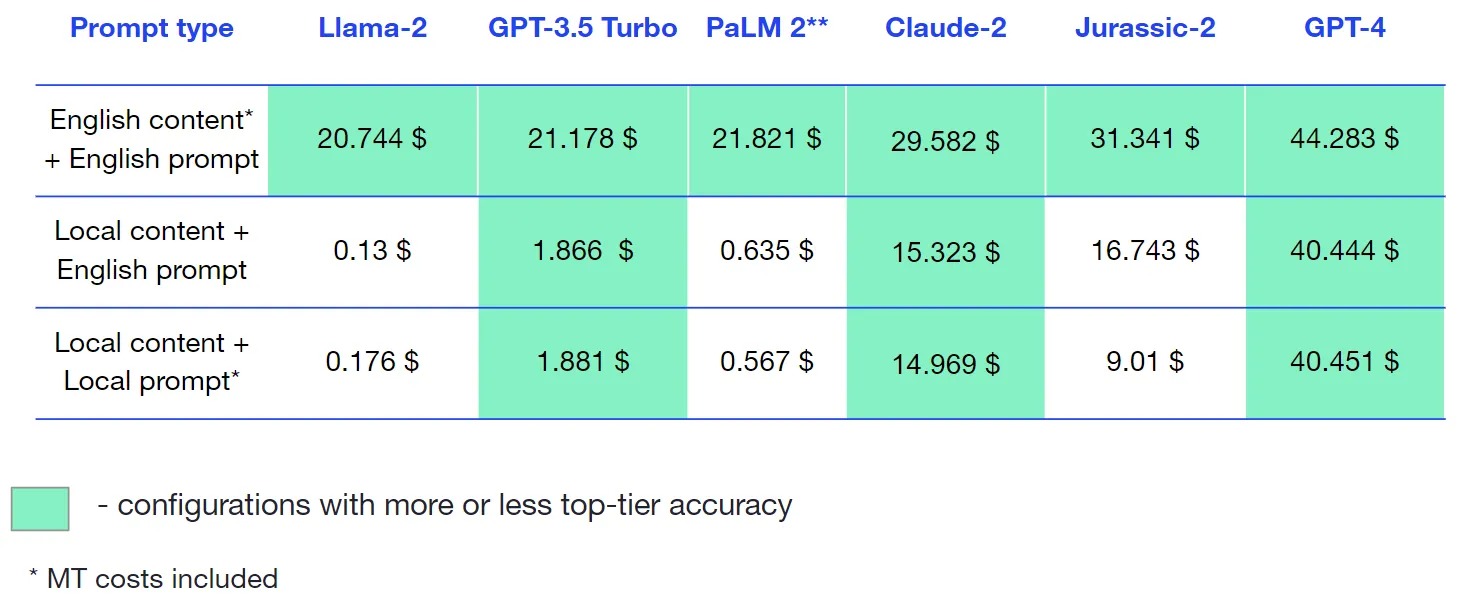
Ukrainian