

Last year, Stanford, MIT, and OpenAI launched an AI Index initiative to track how AI improves on its path towards the singularity.
Hopefully, the index will help to bridge this awful gap between unreasonable conservatism in the industry and ungrounded optimism in the media.
That goes in line with our effort to make AI solution choices based on vendors’ performance rather than on their marketing budgets.
We at Intento are more focused on the current state of the commercially available AI services, and their applicability for specific business uses. However, we do that since May 2017, meaning we also have some data points to track the progress. Here they are.
Disclaimers
The following charts are based on the Machine Evaluation studies we conducted in May, July and November 2017. The last benchmark is much more extensive than the first one, but for now, we stick to its subset we track since May 2017.
We evaluate only commercially available services with pre-built models and a public API. There’s a certain amount of MT Quality improvement available for on-premise solutions, but often that comes at much higher infrastructure costs. Hence we consider our restriction reasonable.
We evaluate MT quality using publicly available WMT2016 News corpus. The MT services we evaluated may have used this corpus to train. However, MT quality we observe and its dynamics suggest there’s no overfitting to this corpus.
We evaluated quality using hLEPOR metric, which measure the difference from a human reference translation. hLEPOR feels quite intuitive, meaning we observe 0.7 hLEPOR as almost human-level quality with just a couple of mistakes per sentence. The same sentence may have 0.3–0.4 BLEU score, which doesn’t feel right.

The main disadvantage of this approach to evaluation is the potential “subjectivity threshold,” when a correct translation gets penalized for being different from the reference translation. However, it’s something we yet have to see, as the current level of MT quality is definitely below this threshold.
For additional details on our approach to MT evaluation check the last evaluation report.
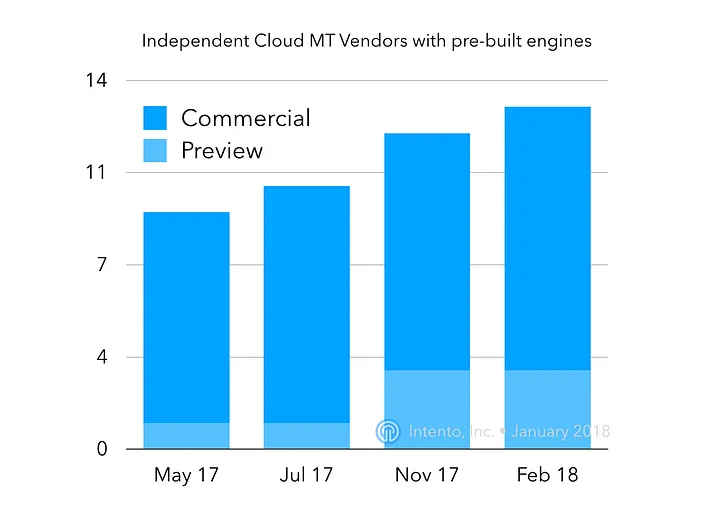
Independent Cloud MT Vendors
We observe data confidentiality terms of Cognitive Services becoming much stricter over time. A couple of years ago many vendors had a clause enabling them to use client data for improving the MT quality, whereas today virtually every MT service apply the same terms as any PaaS, retaining no rights to the clients’ data. We expect this will lead to increasing data-centric segmentation of the MT landscape, with lots data owners monetizing their datasets via their pre-built MT models. A number of independent vendors is a good indicator for that.
In our first benchmark (May 2017) we have evaluated general-purpose MT engines with public APIs from nine independent vendors, with eight being commercially available (SDL, Google, Yandex, Microsoft, PROMT, IBM, Systran, Baidu) and one available for a preview (SAP). In the last evaluation (November 2017) we have evaluated 11 vendors (SAP and DeepL in the preview mode), and one vendor in the preview mode wasn’t added to the evaluation (Tencent)
As of February 2018, DeepL has launched commercially for a limited number of clients, and Amazon has released a limited preview of their MT solution.
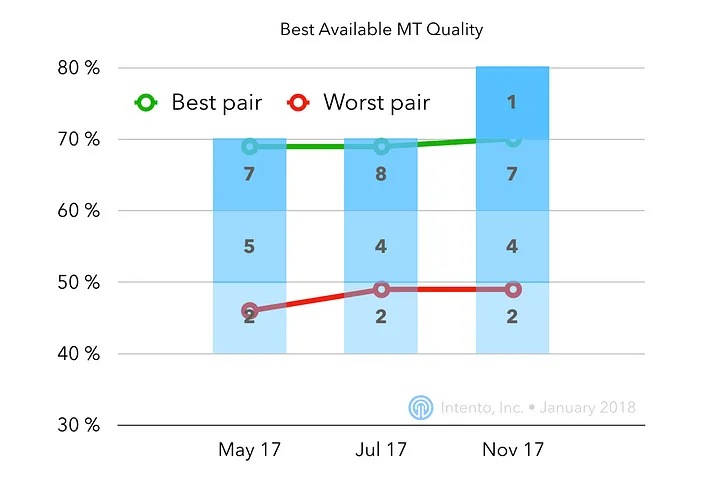
Available MT Quality
We identify several grades of MT quality based on tens of percents on the hLEPOR scale. An interesting thing to track is the number language pairs commercially available at a certain level of MT quality from at least one vendor.
Over time, we expect more and more language pairs available at the good (> 70%) quality. For some of the pairs, we already have this level of quality, which likely means reaching this level for other pairs depends more on getting better training data than on improving the algorithms.
In our first benchmark (May 2017) we have evaluated 14 language pairs (ru, de, cs, tr, fi, ro, zh to en and back), hence for the current retrospective, we limit our scope to those 14 pairs.
In the picture below, for each language pair we took the best available MT quality for this pair among all vendors. Green line indicates the pair with the best MT quality available (it’s de-en), the red line tracks the pair with the worst MT quality available (it’s en-fi). Numbers indicate a number of pairs for each of the MT Quality buckets.
Available MT efficiency
Another way to look at the MT progress is to measure performance/price efficiency. We have tried to capture it using the following formula: efficiency = (hLEPOR in %)² / (USD per 1M symbols). We took prices for the base price tier of all vendors and analysed how many language pairs available per each efficiency level, for the same 14 language pairs May 17 thru Nov 17.
Here’s what we got, also tiered by different efficiency levels and the number of language pairs available at this efficiency.
In the picture below, for each language pair we took the best available MT efficiency for this pair among all vendors. Green line indicates the pair with the best MT quality available (de-en in May, en-zh in July and November), the red line tracks the pair with the worst MT quality available (en-fi in May and July, en-cs in November). Numbers indicate a number of pairs for each of the MT Efficiency buckets.

Conclusions
We see the number of independent MT vendors grows steadily, and we expect it to accelerate, as algorithms and platforms are increasingly democratized, enabling companies possessing high-quality corpora to monetize it without giving away the data (GTCom and DeepL are perfect examples here). Currently, we know only two vendors that enable more or less one-click training of the custom MT engine (Globalese and IBM), all chances it will soon become a category feature for Cloud MT.
Absolute MT quality improves very slowly, and what is not visible is that the performance of less expensive vendors leaped forward during last year. We have introduced the performance/price efficiency to capture these dynamics, and it does that perfectly.


